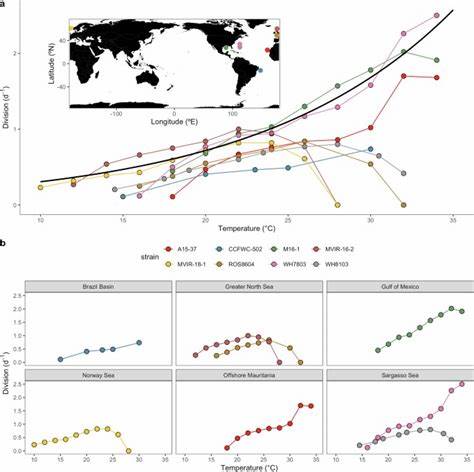
随着信息技术的迅速发展,文字的数字化编码变得尤为关键。Unicode标准作为全球范围内普遍采用的字符编码体系,旨在涵盖世界各种语言文字的符号。作为世界上最复杂且历史悠久的文字系统之一,汉字及其相关的中日韩汉字(CJK)字符在Unicode中长期占据着极其庞大的编码空间。最新版的Unicode 17引入了全新的CJK统一汉字扩展J,添加了超过四千个新字符,再次引发了学界与IT界对汉字书写系统本质及其数字编码挑战的广泛关注。汉字本质上的复杂结构和庞大的字符库,与其他语言的字母表或音素系统有着本质区别。英文仅有26个字母,而汉字的数量早已突破十万,其中绝大部分字符涉及丰富的偏旁部首组合,笔画数量平均达到十二笔左右。
这种高度的象形与表意结合使得汉字的表达信息密度极高,但也带来了数字化编码与输入的难题。新扩展集中的字符很多源自历史书籍、地方文献及方言用字,例如包含大量重复排列的结构复杂的字符、"biang"字等,它们反映了汉字在不同地域和文化中的多样性,尽管部分字符极少见且使用频率不高,却承载着重要的文化与历史价值。Unicode针对这些字符的编码,不仅是为了现代汉语普通话的表达需要,更是对整个汉字文化圈文字遗产的数字保存与传播。值得注意的是,CJK字符的扩容也反映了一种独特的语言文化现象:汉字书写系统并非以音素为中心,而是以独立象形符号为单位,这不同于拼音文字的音节构成。从信息学角度而言,汉字字符的平均笔画数及构成复杂度远高于拼音文字的字母数量,同时单个汉字包含的信息量往往远超单个拉丁字母。因而在编码设计上,汉字系统的需求使Unicode必须分配巨量的代码点以涵盖全范围需求。
新加入的CJK扩展J虽有大量复杂生僻字,但它们的存在对支持多方言、历史档案以及艺术作品的数字化至关重要。事实上,数字字体厂商和操作系统仍在逐步完善对这些新字符的支持。当前常用系统如macOS尚未完全覆盖例如"biang"字等极复杂汉字,未来随着技术普及,全面支持势在必行。此外,垃圾字符、传统与简化字体的差异以及字符的语义模糊性等问题,成为Unicode在汉字编码领域持续面临的核心挑战。对比拼音文字,汉字的输入多依赖拼音输入法或五笔等结构输入法,不具备简单拼写规则,导致使用门槛相对较高。Unicode的努力不仅体现在新增字符,更促进了字形规范的统一和跨文化交流的便利。
值得一提的是,Unicode的设计原则是编码"字符"而非"字形",即同一汉字的不同地域书写风格或字体变体并不占用多个编码点,而是通过字体设计解决。这种方法在确保编码空间高效利用的同时,也允许文化差异的多样呈现。然而,汉字中存在大量的历史变体及罕用字,其编码需求远超普通认知,正是这部分需求推动了如扩展J之类大规模新增字符的出现。虽然目前很多扩展字符的实际使用极为有限,甚至有专家质疑其价值,但正如语言学家所言,Unicode的目标是实现"忠实记录所有长期严肃使用的文字",这使其变成全球文化数字化的基石。日益增长的汉字编码量也映射出中国及东亚文化圈语言文字的丰富性和复杂性,同时促使相关技术不断创新完善。比如,解决笔画极多的复杂汉字如何高效渲染和输入,如何通过数据挖掘统计实际应用频率,优化编码结构与字体设计等,都是未来工作重点。
综上所述,Unicode CJK统一汉字扩展J不仅是一次技术性的字符补充,更是对汉字书写系统多样化的深刻体现。它揭示了汉字语言文化的巨大多样性和历史厚重感,同时也提醒我们汉字数字化道路的漫长与艰巨。只有不断深化对汉字结构、文化语境的理解,以及发挥信息技术的潜能,才能真正实现语言文字的传承与新时代的信息交流需求。未来,随着全球中文信息处理不断升级,Unicode汉字编码的完善将推动中华文化更广泛和深远的数字传播,让这座千年文字的丰碑焕发出新的光彩。 。