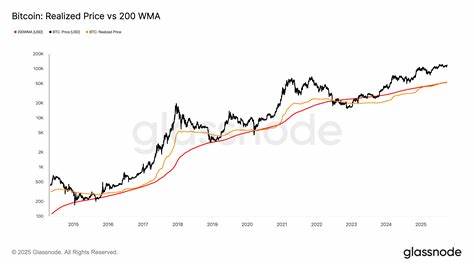
近年来,随着人工智能技术的飞速发展,大型语言模型(LLM)成为推动行业变革的重要力量。然而,关于LLM究竟多大程度上带来实际效益和利润的争论也日益激烈。在这种背景下,区分受限(Constrained)与非受限(Unconstrained)两大类LLM使用场景,能让我们更清晰地理解这一技术在不同业务领域的价值体现及长期可持续性。 所谓受限LLM,指的是那些在输入输出、任务范围和模型规模方面有严格控制的应用。通常,这类用例对生成文本的长度、格式有明确要求,例如限定响应长度少于百余个词,或必须以特定的JSON结构返回结果。这种设计极大地减少了模型产生错误或幻觉信息的概率,同时能控制运行成本,保证算力资源的高效利用。
因其任务单一且可量化,受限LLM的输出很容易被自动化审核及验证,即使出现偏差也不会带来致命的损失。 具体到行业应用,受限LLM广泛参与诸如网页信息抓取、内容摘要生成、自动补全以及基础代码审查等活动。例如Firecrawl在网页数据抓取中的应用,以及光标(Cursor)软件中的标签自动完成功能,都是围绕效率与准确性展开优化。受限LLM的优点在于能够显著提高特定任务的自动化水平,节省人工成本,缩短响应时间,同时由于输入输出的高度标准化,也使得系统更易维护和扩展。 相比之下,非受限LLM使用场景则更为复杂且自由。这类模型往往不对输入长度设限,生成的内容更丰富且多样化,任务也更难以用明确指标衡量效果。
比如利用非受限LLM进行无代码应用开发、复杂问题推理,或是和AI虚拟伴侣的自由交流,均需要模型在较大上下文窗口中理解和生成信息。这种开放的交互方式带来的是更具创造性和个性化的结果,但同时也伴随较高的运算成本以及输出准确性难以验证的问题。 由于非受限LLM输出的多样性和抽象性,其使用效果往往存在较大主观性差异。一位用户可能觉得模型生成的代码冗长无用,而另一位则可能认为已经省去了大量的开发时间。此类应用中,衡量效益的标准趋向模糊,也导致了行业内关于非受限LLM"有用与否"的广泛争论。这类聊天机器人、智能写作工具和开放式问答系统,虽受到用户青睐,但商业化过程中常面临成本控制难题。
从盈利视角看,受限LLM具有显著优势。它们由于操作简单、运行成本低且结果稳定,能够为企业带来稳定的收益。相反,非受限LLM因其需求多变、资源消耗高,利润率不稳定甚至出现亏损风险。一些厂商的研究显示,95%的AI项目未带来实际财务回报,这背后很大部分归因于非受限LLM的高成本且难以量化的效益。 不难理解,为什么业界出现"LLM替代初级开发者但难以取代资深开发者"的说法。经验丰富的工程师擅长提出具体、限制明确的指令,使得模型生成的结果既符合预期又控制成本。
而初级开发者在面对非受限任务时,对生成结果的甄别和优化能力有限,导致工作效率提升不明显,甚至因错误修正增加额外负担。 另一方面,OpenAI作为大型语言模型研发及服务的领先者,自推出ChatGPT以来,在免费提供几乎无限制的聊天接口的同时,也设定了行业定价标准。然而,这种开创性的商业模式,虽然极大推动了用户规模与技术落地,却也埋下了盈利挑战。按月付费而非基于"每个token"计费,导致非受限聊天大量消耗计算资源,整体非盈利化风险增大。 市场竞争也因受限/非受限之分而显现出不同的策略焦点。多数公司趋于打造高性能、复杂非受限模型,力图以卓越智能吸引用户和资本,却忽视了低成本、受限模型在可持续商业模式中的重要性。
实际情况是,用户对更便宜模型的需求几乎不存在,免费模式培养了用户对高质量、全功能无障碍使用体验的期待,使得成本优势无法转化成显著市场优势。 企业在应对这一问题时,面临着两条路径的选择。一方面,继续投入资源支持非受限功能,尽管成本高昂且利润不确定,因害怕被竞争对手抢占市场份额而难以下架高耗能的聊天产品。另一方面,则是寻求创新方式将非受限场景约束化,将复杂任务拆解成一系列标准化、易于验证的小任务,从而实现性能和成本的平衡。 此外,科技公司还需反思是否所有业务场景都需要LLM介入。非必要的复杂功能和过度依赖大型模型,可能带来资源浪费和效益低下。
相较之下,诸如Firecrawl这样专注于受限场景的公司,更可能实现业务盈利及用户认可。 未来的趋势或许是,受限和非受限LLM将更为紧密结合,发挥各自优势。技术层面,不断提升模型效率、减少计算成本,将为非受限用例带来生机。而商业模式方面,基于使用量计费、设置合理限制、增强用户对输出的约束能力,也将在确保收益的同时提升用户体验。 总的来说,区分受限与非受限大型语言模型的应用场景不仅有助于评估技术成熟度和商业价值,更是企业制定AI战略时不可或缺的思路。通过聚焦受限用例,企业可以实现早期盈利和风险管控;而对非受限用例的探索,则推动了AI技术的不断突破和创新。
如何在二者之间找到合理平衡,将成为推动人工智能行业健康发展的关键。 。