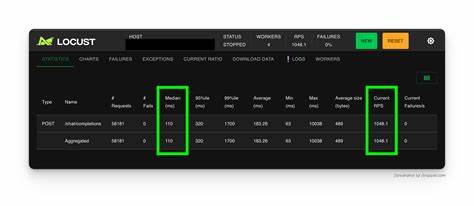
随着人工智能技术的快速发展,尤其是大型语言模型和深度学习应用的普及,越来越多的开发者和企业希望在本地部署复杂且不受限的模型。然而,传统单纯依赖CPU处理的模式往往难以满足高并发请求的需求,尤其是在寻求每秒千次请求(1k RPS)响应速度时,面临诸多挑战。高并发、高性能、低延迟已成为硬件架构设计的关键考量。本文将深入探讨硬件选择的关键因素及实际部署中的优化策略,帮助读者更好地理解如何打造满足1k RPS的硬件环境。理解1k RPS的硬件需求,首先要明确所运行模型的复杂度与资源消耗。很多开发者曾尝试在仅使用CPU的服务器上运行未经过滤或“非审查”的语言模型,但反馈普遍反映单次查询耗时长达数分钟,这显然和需求相差甚远。
此种情形下,性能瓶颈主要源于模型计算量大、CPU并行能力有限以及内存带宽不足等方面。因此,为实现每秒千次请求这一高性能指标,必须依赖具备强大并行计算能力的硬件资源。GPU(图形处理单元)因其强大的并行计算能力,成为支撑高性能机器学习推理的首选设备。与CPU相比,GPU内含数千个核心,能够同时处理大量张量计算任务,极大提升深度神经网络的推理效率。在选择GPU硬件时,模型的大小与内存容量成为重点考量。若模型尺寸较大,例如包含数十亿参数的变换器模型,所需显存资源也随之增加。
一般建议将单个模型占用的显存乘以1,000(对应1k RPS),然后根据硬件显存容量来估算所需的GPU数量。此外,GPU的计算性能(TFLOPS级别)和带宽也影响整体响应速度。在硬件选型过程中,除了显存容量,GPU的架构特点同样重要。最新一代的NVIDIA A100、H100等产品,因具备更高的张量核心数量和更优的内存管理机制,被广泛应用于人工智能推理任务。新兴的AI加速卡如Google的TPU和苹果的M系列芯片,也在特定场景提供部分优势。不同硬件平台在能效比、价格和易用性方面存有差异,企业和开发者应根据具体需求合理权衡。
除了GPU外,CPU依然承担着调度、数据预处理和通信协调的重要角色。具备多核和高主频的CPU能够更有效地支撑整体系统性能。内存速度与容量也是提升整体响应能力的关键因素,快速的RAM读写能够减少数据传输瓶颈。存储方面,使用NVMe SSD等高速硬盘可有效缩短模型加载和缓存时间。构建支持1k RPS的系统,还需关注软件层面的优化。模型量化、结构剪枝和蒸馏等技术能有效减少模型计算资源消耗,从而降低对硬件的负载。
分布式推理方案通过多台机器协同工作,能够更好地扩展处理能力,实现更高的并发请求响应。合理设计负载均衡和请求调度机制,避免单点过载,是维护系统稳定性的关键。在部署环境方面,现场环境对硬件设施的要求同样不容忽视。高密度GPU服务器往往需要良好的散热系统和稳定的电力供应。数据中心环境需要考虑网络带宽和延迟,确保前端请求能够被快速吞吐和响应。利用容器技术和虚拟化软件管理多个推理实例,有助于提升硬件使用效率和灵活调度资源。
近年来,一些云服务商开始提供支持未经过滤大模型的API,试图解决本地部署带来的复杂性与成本压力。但由于使用限制和隐私安全等原因,部分开发者依然倾向于本地运行模型,自主管理数据和计算资源。在这一背景下,合理设计硬件架构显得尤为重要。整合多种硬件优势,配合高效的软件工具,能够大幅改善用户体验和系统鲁棒性。未来,随着硬件性能的持续升级以及人工智能算法的优化,普通开发者运行大规模复杂模型的门槛将进一步降低。支持1k RPS甚至更高请求量的本地推理方案将成为更多场景的主流选择。
与此同时,开放和透明的模型生态及更灵活的硬件方案也将促进AI技术在更多领域的深度应用。综上所述,实现支持每秒千次请求的硬件方案,必须综合考虑模型规模、显存需求、GPU架构和CPU性能,辅以内存及存储的高速支持。通过合理的硬件组合,加上软件层面的优化和负载调度机制,方能打造出高效、稳定且具备扩展能力的AI推理环境。未来,随着技术的不断进步和生态的完善,更多开发者将能享受到高速、大规模模型推理带来的便利与创新机遇。