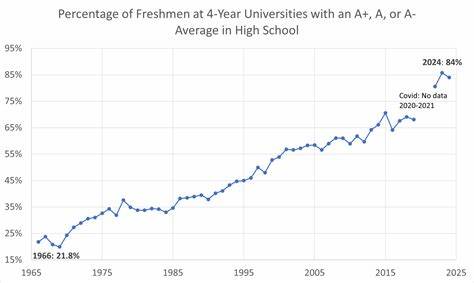
在现代互联网技术快速发展的背景下,HTML作为网页结构的核心语言,其解析技术的进步直接影响了前后端数据处理和内容提取的效率。近年来,随着网络数据量的激增和多样化,传统的HTML解析工具在性能和灵活性方面面临诸多挑战。针对这种需求,一款以C语言实现且拥有自定义匹配语言的HTML解析器应运而生,它不仅带来了速度优势,还提供了灵活而强大的查询能力,成为开发者拆解网页信息的利器。 这款解析器核心由C语言编写,最大程度地保证了运行速度和资源占用的优化。作为系统级语言的代表,C语言以其高效性和跨平台特征,在编写底层解析组件和构建稳定工具方面展现出无可比拟的优势。解析器通过直接操作内存和精细管理数据结构,使得对HTML文档的读取和分析过程更加迅速,同时支持大规模文档处理而不出现显著的性能瓶颈。
与一般HTML解析库不同的是,该解析器引入了其独有的匹配语言,这种语言旨在简化和增强HTML元素的定位及筛选过程。匹配语言设计直观,支持类CSS选择器的语法扩展,允许用户通过简练的表达式精确指定目标标签、属性和文本内容。其核心优势在于不仅支持基本标签如div、span的快速定位,更能复杂组合属性匹配、层级判断乃至正则表达式的引用,实现灵活多样的查询需求。 例如,通过简单的表达语句,开发者即可轻松获得所有class包含“tile”的div元素,或筛选出不包含子标签且内部长度为零的任意标签。更高级的用法还支持过滤特定层级深度的链接或者动态处理HTML中的PHP标签,实现对复杂页面结构的精细抓取。此外,解析器针对HTML quirks(非标准闭合标签等)提供了可选关闭或开启的处理策略,方便用户根据实际网页规范调整解析准确度。
该工具不仅支持命令行操作,也能作为库集成到项目中,通过简单的API调用完成HTML内容的提取和数据转换。用户可通过安装命令或源码编译轻松完成环境搭建,支持多种构建选项以满足不同性能和功能需求。针对程序员的调用习惯,匹配语言还兼容了类似sed、cut、tr等文本处理工具的链式输出,进一步丰富了数据后期分析和清洗的方式。 在实际应用层面,这款HTML解析器表现尤为出色。其灵活的匹配语法适合用于网页数据抓取、论坛内容提取、新闻信息聚合等多种场景。许多开源项目和爬虫系统都采用了该工具作为核心解析模块,显著提升了页面访问速率和数据准确性。
结合自定义JSON格式输出功能,用户可以将解析结果直接结构化为方便后续处理和存储的格式,大大简化了数据链路的整体复杂度。 尤其值得关注的是,这款解析器的设计不仅着眼于速度和灵活性,更重视易用性和扩展性。手册中详细描述了匹配语言语法要点、字段定义、嵌套结构及常见用例,配合色彩高亮的命令行文档阅读环境,帮助用户快速掌握并发挥出强大的表达能力。通过精妙的语法设计,用户可以轻松完成多级筛选和内容提取任务,甚至支持集合操作和复杂条件判断,实现对HTML文档的深度解析。 此外,项目积极支持社区发展,提供了多语言绑定接口,如Python接口,使得其在多种开发环境下均能被轻松调用。这种跨语言支持极大地拓展了其生态适用范围,无论是系统集成、自动化测试还是数据分析管道都能够无缝对接。
依赖稳定的代码库和活跃的社区贡献,工具的维护和升级频繁,持续引入新特性和性能优化,保证用户体验持续提升。 结合具体示例,可以看到诸如从论坛帖子中抓取用户头像信息、分析帖子时间戳、筛选会议时间序列数据,甚至处理包含复杂正则表达式匹配的链接抽取任务,都能通过匹配语言简洁表达并直接获得高质量结果。复杂查询和多步骤数据处理中,匹配语言通过块结构和管道命令提供了全面控制,实现了与传统解析脚本无法比拟的灵活度和效率。 综上所述,这款基于C语言的HTML解析器以其高性能的运行效率和创新的自定义匹配语言,为网页数据提取领域注入了新的活力。它在保证底层处理速度的同时,通过专用查询语言极大丰富了用户操作维度,满足了复杂且多变的网页结构解析需求。对于需要快速可靠抓取和分析网页数据的开发者而言,这款工具提供了极具竞争力的解决方案。
面对未来,随着网页技术的持续演进和动态内容的日益普及,该HTML解析器也在不断进化,融入更多现代特性,如更智能的异常处理、更丰富的DOM模型支持以及对新兴网页技术的适配能力。开发者社区的积极参与和活跃反馈为项目注入持续动力,推动着解析工具在功能完善性和应用广度上双向提升。 总的来说,这个HTML解析器是对传统网页解析工具的一次技术革新,通过结合底层C语言优化和高层匹配语言设计,打造了一款兼顾速度和灵活性的利器。无论是数据采集、新媒体内容分析,还是复杂的网页信息抽取,都能从中受益匪浅,成为数字信息时代不可或缺的解析助手。随着其用户基础的扩大和功能的扩展,注定会在网页解析领域继续发挥重要作用。