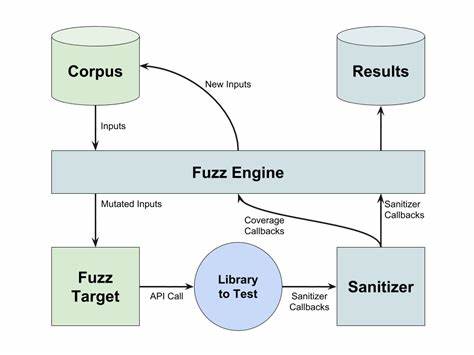
近年来,随着人工智能技术的飞速发展,强化学习作为一种重要的机器学习范式,因其自主探索和优化能力,成为智能体训练的重要路径。然而,传统强化学习框架在训练复杂多轮智能体时,往往面临繁琐的训练环节、难以适配大规模语言模型以及高昂的开发成本等挑战。针对这些困境,开源项目ART(Agent Reinforcement Trainer)横空出世,凭借其创新的设计理念和强大的功能特性,迅速引起了业界广泛关注。ART是一款基于GRPO(General Reinforced Policy Optimization)强化学习算法,专门为训练多轮智能体设计的开源工具。它将智能体训练中的复杂细节封装在后端服务中,开发者只需调用兼容OpenAI接口的客户端,便能轻松实现对大型语言模型的自主优化,大幅降低了训练门槛和开发难度。ART的核心优势之一在于其独特的训练循环设计。
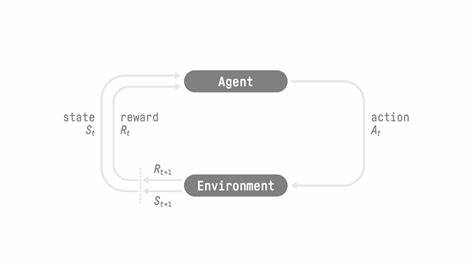
训练流程分为推理和训练两个阶段,首先通过客户端发起的多轮推理请求,智能体在真实或模拟环境中完成任务,同时系统记录每一次交互的状态、动作和反馈信息形成轨迹(Trajectory)。随后,开发者为每条轨迹分配奖励信号,定量评估智能体表现。奖励计算完成后,轨迹数据被传递回服务端进行GRPO算法训练。训练过程中,服务端会基于最新模型检查点更新模型参数,并保存优化后的低秩适配器(LoRA),保证了模型的高效迭代与快速更新。ART不仅简化了训练环节,也通过无缝加载新的LoRA版本,实现了性能提升时推理请求的不间断,保障了训练与应用的高效衔接。这种分布式设计使得训练可以在拥有GPU的独立机器上高效并行进行,而客户端保持轻量级,适配多种实际业务场景。
在支持的模型范围方面,ART兼容现有主流基于vLLM和HuggingFace-transformers的因果语言模型,保证了广泛的适用性和灵活性。虽然目前某些模型如Gemma 3尚未支持,但开发团队积极响应社区反馈,持续扩展模型兼容清单,为更多智能体训练需求提供专业支持。ART已成功应用于多种游戏和任务训练检验中,如2048游戏、时序线索推理、井字棋和密码游戏等,其中利用Qwen 2.5系列大规模语言模型展现了卓越的学习能力和策略优化效果,实验证明了ART在复杂任务场景下的高效与稳定。值得一提的是,ART通过开放式的设计,欢迎开发者通过GitHub和Discord社区积极参与贡献,共同推进项目迭代和功能完善,形成了蓬勃发展的开源生态。此外,ART在真实世界任务中的应用前景同样广阔。通过其代理智能体ART•E,团队展示了如何配合大型语言模型实现复杂邮件检索任务的智能化自动处理,显著提升了实际工作效率和用户体验。
这一案例充分体现了ART对垂直行业智能化转型的助力潜力。总体来看,ART集合了开源、易用、高效三个关键要素,为多轮智能体训练提供了理想的技术平台。其模块化架构、开放接口设计和先进的GRPO算法实践,赋能研究者和开发者轻松探索强化学习的更多可能,推动智能体技术在游戏、客服、自动化办公等领域的广泛落地。当前开源社区对ART的发展高度期待,更多创新用法和优化方案正在不断涌现。未来,随着多模态模型和自监督学习技术的融合,ART有望进一步扩展能力边界,打造更加智能化、可控且自适应的代理系统。关注ART,意味着站在智能体训练技术前沿,享受开源智能训练带来的便捷与创新。
无论是科研探索还是商业应用,ART都为实现高效智能代理交互与训练树立了新标杆,堪称下一个强化学习框架的重要里程碑。