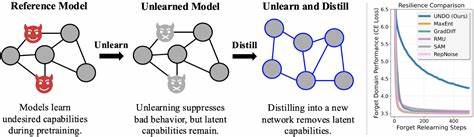
随着人工智能技术的快速发展,机器学习模型的训练与应用已渗透到社会的各个角落。然而,随之而来的是对于模型遗忘不必要或敏感信息的需求日益增长,特别是在保护用户隐私和满足合规性要求方面。传统的机器学习模型在执行遗忘操作时面临诸多挑战,特别是缺乏足够鲁棒性的遗忘方法往往容易被逆转或绕过。近期,蒸馏技术在增强模型遗忘能力中的独特价值被学界广泛关注,这为实现稳定、有效的机器学习模型遗忘开启了新篇章。蒸馏技术本质上是通过训练一个“学生模型”去模仿一个“教师模型”的输出表现,从而在维持模型核心功能的同时实现轻量化或特定性能优化。而最新研究表明,将蒸馏技术应用于“未暴露模型”(即未接触过需要遗忘信息的理想模型)与遗忘模型之间,能够有效提升忘记过程的鲁棒性。
这种方法避免了仅靠输出微调所导致的遗忘不彻底和易被复原的问题。通过训练一个随机初始化的学生模型去模仿已经处理过遗忘操作的教师模型,不仅能转移出希望保留的能力,还能有效剥离掉不希望存在的敏感信息,实现更为彻底的遗忘效果。基于此理论,研究团队提出了一种称为“UNDO”(Unlearn-Noise-Distill-on-Outputs)的创新算法。UNDO通过将遗忘模型的输出与一定比例的噪声混合,之后对该部分进行蒸馏训练,在提升计算效率的同时,显著增强了遗忘的鲁棒性。该方法实现了算力和鲁棒性的可调节平衡,帮助研究者和工程师根据实际应用需求灵活调整资源投入。UNO的实验结果令人振奋:在合成语言和算术任务上表现出更优的安全鲁棒性,最强配置下,能够用仅占到从头训练计算量60%至80%的资源与极少的预训练数据(仅0.01%带标签数据)实现近似从零开始训练并且完美筛选数据的模型遗忘效果。
更重要的是,UNDO在更具现实意义的“武器大规模杀伤性代理数据集”(WMDP)基准测试中展现出的稳定性,表明蒸馏方法有潜力成为工业界实现模型遗忘的标准流程之一。通过将遗忘操作置于蒸馏之前,常见的蒸馏实践不仅不再削弱遗忘效果,反而得以稳固和强化。这为模型在面对敏感信息或者法规更新时快速响应提供了有效途径。此外,UNDO降低了对大量标注数据的依赖,特别适用于数据稀缺或隐私敏感的使用场景。现阶段,许多大语言模型和应用系统正面临如何快速可靠地移除特定数据或知识点的突出难题,传统再训练方法成本巨大且耗时长,且技术门槛高。蒸馏助力的遗忘技术则为工程部署带来极大的便捷和经济效益。
纵观目前机器学习模型的安全需求,对模型能力进行精细化控制已成为关注焦点。蒸馏技术为此提供了坚实的技术支撑。未来,结合多模态学习、联邦学习以及增强隐私保护机制,蒸馏强化的遗忘方法将缓解数据泄露风险、提升模型管理效率,并推动人工智能合规发展。用户数据保护与模型安全已不仅仅是技术挑战,更是社会责任和伦理体现。蒸馏技术以其独特的稳健性优势,为实现机器学习领域内可控、可信的遗忘机制注入了新活力。整体来看,蒸馏技术为遗忘领域带来的革新不仅体现在理论突破,更在于实用性的显著提升。
随着更多研究成果的堆积与产业界的深度应用,未来机器学习模型将更智能地实现“忘记”与“记住”的精妙平衡,助推智能系统更好地尊重用户隐私、强化安全防护。可以预见的是,伴随着技术的不断完善与优化,蒸馏强化遗忘方法将在数据敏感性日益加剧的背景下发挥越来越重要的作用,成为机器学习领域不可或缺的核心工具之一。