在当今快速发展的人工智能和大数据时代,如何高效地进行大规模相似性搜索成为技术领域关注的焦点。作为最前沿的解决方案之一,HNSW(分层导航小世界图)凭借其卓越的搜索性能和低延迟表现,逐渐成为构建向量搜索引擎的重要数据结构。同时,基于Redis平台扩展的向量集合功能,更是将HNSW的优势与Redis灵活高效的内存数据库特性结合,为各种应用场景提供强有力的支持。 HNSW是一种通过构建分层的小世界图实现近似最近邻搜索的抽象数据结构。其核心思想源于小世界网络理论,通过图结构中的导航机制,实现对海量向量数据的快速定位和查询。相比传统的暴力搜索方法,HNSW极大地降低了计算复杂度和内存占用,同时还能保持较高的搜索准确度。
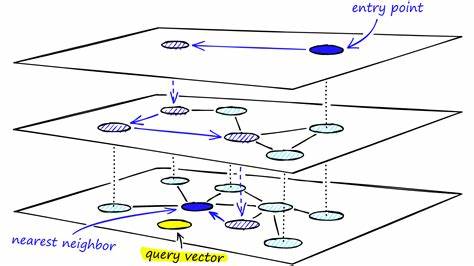
Redis作为一个高性能的内存数据库系统,近年来不断扩展其功能,特别是在向量数据处理方面取得了重要突破。Redis向量集合模块引入了对向量类型数据的存储、管理和检索功能,支持多种相似性度量和索引方式。其中,HNSW算法被集成为其主要的索引机制,结合Redis的高效数据操作能力,为开发者和企业提供了简洁易用且功能强大的向量搜索解决方案。 通过视频介绍可以了解到,Redis向量集合中采用HNSW结构的核心优势包括三方面。首先,分层结构设计使得搜索过程逐层收敛,利用高层的全局视野快速缩小搜索范围,再结合低层的细粒度连接完成精确定位,显著提升搜索速度。其次,图中的导航边设计遵循小世界网络的特性,确保节点之间路径短,遍历效率高。
最后,动态插入与删除操作的支持,使得向量集合可以灵活应对数据量和内容的变化,满足实时场景需求。 技术层面上,HNSW索引由多个图层组成,最顶层包含少量节点,代表向量空间的全局结构,而底层包含所有数据点形成详尽的邻接关系。检索时,搜索从顶层开始,沿着邻近距离更短的节点逐层下探,直到最底层完成搜索。这样的结构设计极大地减少了搜索步骤,并充分利用了局部邻域相似性的特性。 Redis对向量数据的支持则通过专门的数据类型和命令集实现。用户可以利用Redis强大的内存存储能力,将高维向量数据快速载入和维护,同时结合HNSW索引执行近似最近邻查询。
这样的组合为图像识别、自然语言处理、推荐系统等领域提供了坚实的数据基础和计算能力。 在实际应用中,利用Redis向量集合及其HNSW索引,可以有效提升搜索引擎的响应速度和检索准确率。尤其是在面对海量数据时,传统的线性搜索方法显得力不从心,而基于HNSW的索引机制则以其优异的性能保障用户体验。在电商平台,用户商品推荐、相似商品推荐等场景均能借助该技术实现个性化和实时响应。在医疗健康领域,图像和基因数据的相似性检索同样能够借助Redis+HNSW实现高效管理和分析。 除此之外,HNSW结构的多层次设计使其具有良好的扩展性和鲁棒性。
Redis在该基础上提供了丰富的API接口,便于开发者根据具体业务需求进行灵活定制和优化,支持不同维度、不同距离函数的向量搜索。同时,结合Redis的持久化与分布式能力,能够保障系统在大规模生产环境下的稳定性和高可用性。 总结来看,将HNSW作为抽象数据结构应用于Redis向量集合,是大规模相似性搜索领域一次重要的技术创新。它不仅提升了搜索的效率和准确性,也为向量数据管理树立了新的行业标杆。未来,随着人工智能技术的不断进步和应用领域的多样化,Redis与HNSW的结合必将在智能检索、数据挖掘、个性化服务等方面发挥更大价值。对于技术从业者而言,深入理解HNSW的结构原理及其在Redis中的实现,将极大地助力构建高效、先进的数据处理平台,满足新时代海量数据背景下的智能搜索需求。
。