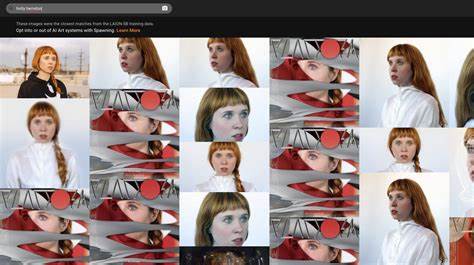
在人工智能蓬勃发展的时代,数据成为了支撑各类智能应用的重要资源。无论是语音识别、图像识别,还是语言生成模型,背后都离不开大量的训练数据。然而,这其中蕴含的隐私风险却常常被忽视,许多用户甚至无法得知自己的个人数据是否被用于了人工智能的训练。为回应这一需求,平台“Have I Been Trained?”应运而生,旨在为公众提供一个便捷手段,用以检测个人数据是否被纳入了人工智能训练的数据库。 “Have I Been Trained?” 作为一个在线检测服务,主要功能是调查用户提交的信息是否存在于公开已知的训练数据集中。使用者只需输入诸如邮箱、用户名或其他身份标识符,平台便会对比各种公开的训练数据记录,从而判断该信息是否已被用于训练目的。
这样,用户可以及时获悉自己的数据是否被第三方利用,进而采取相应的保护措施。 该平台不仅支持个人查询,还对企业用户开放API接口,便于更大规模地进行数据监管。此外,平台采用了严格的隐私政策,确保用户提交的查询内容不会被保留或用于其他商业用途,力求在保护用户隐私和实现透明之间达到平衡。 近年来,人工智能在各领域的广泛应用推动了数据市场的快速发展。大量的数据被收集、整理并用作训练模型,这其中包含了很多来自个人的敏感信息。许多用户缺乏相关意识,也没有明确的授权,导致隐私泄露频发。
而“Have I Been Trained?”的出现正是为了回应这种担忧,帮助用户揭示信息背后的真相。 除了基础的检测与告知功能,该平台还结合了NSFW(不适宜工作环境内容)过滤器,确保用户在查询过程中不接触到潜在不适的训练数据内容。这一设计体现了对用户体验和安全的进一步关怀。同时,网站使用了Google reCAPTCHA技术防止恶意访问,提高服务安全性。 在实际应用中,用户通过输入邮箱或用户名即可迅速获得查询结果。若发现个人数据被包含在模型训练集中,用户应当意识到存在一定的安全风险,并考虑更换相关账户信息或增强密码复杂度。
此外,用户还可以配合其他隐私保护措施,比如使用虚拟专用网络(VPN)、定期清理社交媒体信息以减少数据曝光。 对于开发者和研究人员而言,“Have I Been Trained?” 提供了一个有价值的工具来了解训练数据的范围和边界,促进负责任的人工智能开发。开放的API接口使得大型平台可以将此检测功能集成进自身的数据治理流程中,从而提前识别潜在的隐私问题,优化数据管理策略。 未来,随着越来越多的数据被用于训练更强大的人工智能模型,监管和透明度需求也将持续增长。类似“Have I Been Trained?” 这样的平台不仅体现了科技创新的力量,也彰显了数字时代用户对隐私保护的诉求。通过推广筛查和警示,能够有效提升公众的数据安全意识,推动相关法律法规的完善和执行。
总结而言,“Have I Been Trained?” 是人工智能时代中一项重要的隐私保护利器。它不仅帮助个人用户揭示自己数据的使用情况,还为企业和开发者提供技术支持,促进更为安全、透明的人工智能生态。面对日益复杂的大数据环境,掌握并合理利用这一工具,成为现代数字公民维护自身权益的关键一步。随着社会对数据隐私的关注不断增强,相信该平台将持续完善服务功能,为广大用户创造更安心的数字生活体验。