随着人工智能技术的飞速发展,向量搜索已成为诸如语义检索、推荐系统和增强式生成(RAG)等领域的核心组件。面对海量高维向量数据,传统数据库架构显然难以胜任其性能和弹性需求。YugabyteDB作为一款新兴的分布式SQL数据库,通过创新的向量索引架构,为现代AI工作负载提供了理想的解决方案。它不仅兼具PostgreSQL的SQL兼容性,还引入了模块化的分布式向量引擎USearch,实现了高效且可扩展的近似最近邻(ANN)搜索能力。 YugabyteDB的向量索引架构充分借鉴并融合了最新的数据库设计理念与向量检索技术。用户可以在熟悉的SQL环境中定义向量列、创建索引并执行查询,具有极强的易用性。
通过pgvector扩展,用户可以直接在PostgreSQL兼容的接口实现基于向量的搜索操作,免去复杂的学习成本,实现快速落地。同时,底层采用经过优化的分布式存储和计算引擎,保证了索引和查询的高性能和稳定性。 架构的核心创新在于Vector LSM(Log-Structured Merge-tree)抽象层。这一模块化设计使得向量索引的逻辑与数据库核心引擎解耦,方便后续集成多种ANN技术。Vector LSM类似于传统LSM树,但专为向量索引量身打造。其流程涵盖向量数据的内存吸收、基于HNSW算法(如USearch)的内存索引构建,再将满载的内存数据异步持久化为不可变的向量数据块,实现性能与数据安全的平衡。
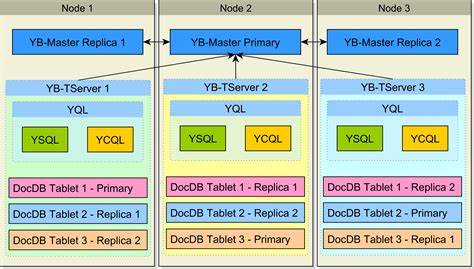
查询时,系统会在内存及磁盘中的所有向量索引实例间并行搜索,并结合多版本并发控制(MVCC)进行过滤与合并,产出最终稳定一致的结果。 YugabyteDB将向量索引与主表实现紧耦合的共分区设计,即向量索引和对应数据存储在同一分片(tablet)内。这种设计大幅降低了跨节点数据访问的延迟,使得嵌入向量与其元数据能够高效本地联结。它让过滤条件推送变为可能,使得SQL谓词和向量搜索能共同执行,减少网络开销和计算消耗。此外,共存于同一Raft日志中意味着索引更新与数据一致性由分布式共识协议保障,实现事务的原子性和持久性,提升了系统的容错能力。 为了支撑大规模的向量工作负载,YugabyteDB的架构充分利用了分布式特性。
所有数据被自动切分成多个可独立管理的tablet,每个tablet维护部分数据与索引的本地副本。查询时会并行地在所有tablet上发起搜索,局部计算Top-K结果,最终汇总成全局最优解。这种Fanout和局部筛选的协同方式避免了单点瓶颈,显著提升吞吐量和响应速度。系统还支持动态扩容,自动均衡数据与计算负载,甚至会根据数据增长自动拆分单个tablet以保障持续性能。 在底层存储与一致性方面,YugabyteDB同样引入了企业级特性。向量索引基于事务性存储引擎,通过MVCC管理数据版本,确保读写操作获得一致视图,支持分析和长时间查询。
持久化机制采用写前日志(WAL)与RocksDB持久存储,崩溃恢复时通过日志重放保证数据及索引不丢失。此外,向量ID与数据版本绑定,使得索引查询在更新或删除时依然准确无误。 USearch作为YugabyteDB的核心向量索引后端,展现了其性能及灵活性优势。它采用轻量级且SIMD优化的C++单头文件实现,定位于速度极致优先,远超传统FAISS等库。其支持基于磁盘的内存映射索引,避免了整个向量库必须加载入内存的限制,特别适合含数十亿级向量的大数据场景。USearch内置了谓词下推功能,能将MVCC条件直接作用于ANN遍历过程,降低后期筛选开销,有效缩短响应时间。
未来还计划支持用户自定义距离度量,满足不同行业如GIS或化学分子领域的专用检索需求。 此架构及其所依赖的技术栈,使YugabyteDB在面向云原生、全球分布的AI场景中具备天然优势。其支持跨多云、多区域部署,且数据和索引分布策略能根据地域和服务需求智能选择,提高响应效率和用户体验。结合PostgreSQL的丰富生态和SQL友好的交互方式,开发者能够快速构建语义搜索、推荐引擎或RAG应用,轻松实现AI原生数据库的目标。 综上所述,YugabyteDB通过其创新的向量索引架构,为现代AI应用提供了高性能、弹性、安全且易用的数据库解决方案。它突破了传统向量数据库在扩展性和一致性上的瓶颈,融合了分布式SQL的可靠性与ANN搜索的高效性,成为构建大规模智能应用的理想平台。
随着AI场景持续多样化和复杂化,YugabyteDB无疑将在推动行业发展和技术进步中扮演重要角色,助力企业迈向智能化的未来。