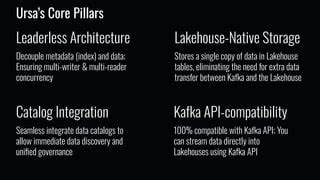
随着数据量的指数级增长,现代企业对于数据处理和分析系统的需求日益增加。数据湖仓理念逐渐兴起,融合了数据湖的低成本存储优势和数据仓库的事务保障能力,成为下一代数据架构的关键方向。然而,在实时数据流传输与整合的过程中,传统系统面临诸多挑战。Ursa作为一种湖仓原生的Kafka兼容数据流引擎,凭借其独特的架构设计和技术创新,带来了颠覆性的性能提升和成本降低,成为业界关注的焦点。数据湖仓架构的崛起是现代数据管理发展的重要里程碑。它一方面保留了数据湖利用廉价对象存储实现大规模数据存储的优势,另一方面通过融合数据仓库的ACID事务功能,实现了数据一致性与可靠性的保证。
在这一模式下,实时数据的摄取和处理变得尤为关键。传统的实时数据流处理依赖如Apache Kafka这样的专用消息系统,通过领导者复制和磁盘存储保证低延迟和数据一致性。然而,这些设计在跨可用区的云环境下往往带来巨大的网络流量和存储资源浪费,进而导致显著的基础设施开销增加。Ursa的诞生源自于对上述痛点的深刻洞察。作为一个无领导者(leaderless)、云原生且与Kafka兼容的数据流引擎,Ursa摒弃了传统Kafka中领导者复制机制,直接将数据写入存储在对象存储上的开放湖仓表中。该设计极大程度上简化了数据流管道,省去了中间代理磁盘存储和外部数据连接器,从而极大地减少了网络通信和存储资源的消耗。
技术层面,Ursa通过无领导结构消除了系统中单点故障和领导者瓶颈,提高了整体系统的可扩展性与弹性。它支持精准一次(exactly-once)语义,确保数据完整性和一致性,满足企业对数据准确性的高要求。同时在吞吐量和延迟表现上,Ursa可媲美传统Kafka集群,做到近实时传输和处理。该平台的云原生设计最大限度地发挥了云对象存储的弹性和高可用特性,使得数据存储和管理更加灵活和经济。通过实验数据可以看出,Ursa在性能指标上实现了与传统Kafka系统相匹配,在基础设施成本上则降低了高达10倍。对于云端大规模数据摄取和实时分析场景尤为适用。
Ursa的出现不仅仅是一种技术创新,更象征着数据流处理领域的理念变革。它将实时流式处理与湖仓架构进行了深度融合,推动了数据处理从"消息中间件+外部连接器"的复杂模式走向更加紧密和高效的本土集成模式。这样的趋势将极大地简化数据工程的实施难度与维护成本,有助于企业快速实现数据驱动的业务创新。企业在面对海量数据并发传输及分析需求时,如何选型数据流处理平台成为关键。Ursa凭借其无领导架构和云原生特性为用户提供了极具吸引力的选择路径。其直接写入湖仓表的设计减少了数据处理路径上的多余环节,缩短了数据落地时间,提升了整体系统响应速度。
此外,Ursa全面兼容Kafka API,方便用户平滑迁移现有Kafka工作负载,无需大规模改造现有基础设施,实现快速落地和复用。从应用视角看,Ursa在金融风控、智能制造、互联网广告和物联网数据监控等领域展现出极大潜力。在这些场景中,低延迟、高吞吐且成本可控的数据流处理对实时决策和业务优化至关重要。Ursa所提供的湖仓原生流引擎解决方案恰好契合这些需求,推动行业数字化进程。未来,随着云计算和对象存储的进一步普及,湖仓架构和实时流处理的边界将会更加模糊融合。Ursa代表了这一领域革新的方向,持续优化流处理引擎架构,提升系统健壮性和智能化水平,是促进企业数据资产价值最大化的重要支撑。
总之,Ursa作为一种与Kafka兼容的湖仓原生数据流引擎,突破了传统流处理架构的瓶颈,通过创新的无领导设计和云原生实现,显著降低了基础设施成本的同时保障了高性能和高可靠性,成为推动实时湖仓数据架构发展的有力引擎。对于数据驱动的现代企业而言,选择并投入Ursa技术体系,将助力其在竞争激烈的数字经济时代抢占先机,实现数据价值的持续释放与增长。 。