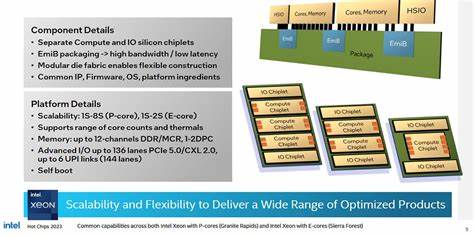
随着数据中心工作负载对并行计算与带宽的不断增长,处理器厂商在架构设计上做出了截然不同的取舍。Intel 的 Xeon 6 平台通过更激进的 chiplet 方案,将计算芯片与 IO 芯片拆分为独立模块,并在逻辑上维持单片式体验;这种设计在提高可扩展性和芯片利用率方面有明显优势,但也带来了对互连和缓存一致性网络更高的要求。通过 AWS r8i 实例上可观察到的 Xeon 6 6985P-C 实例性能,可以对其内存子系统的真实表现做出较为全面的评估。 首先从封装与片上组织说起。Xeon 6 把计算芯片(compute dies)与 IO 芯片(IO dies)并排布局,计算芯片上只保留核心和 DRAM 控制器,IO 芯片承载低速 IO 与加速器。计算芯片采用 Intel 3 工艺以提高能效和频率潜力,而较慢的 IO 与加速单元迁移到单独的 die 有助于提升整体良率并缩短设计周期。
芯片间的物理连接依赖 Intel 的 EMIB(嵌入硅桥)技术,逻辑上则通过一个扩展的 mesh 互连网络实现"单片"视图。在计算 die 的边界处,Xeon 6 引入了称为 Modular Data Fabric(MDF)的网格停靠点来处理跨 die 的 mesh 协议,这类似于 AMD 在片间互联上对 Infinity Fabric 的封装逻辑。 在 microarchitectural 层面,AWS 上的 Xeon 6 6985P-C 核心为 Redwood Cove 微架构,单芯片配备 96 核,每核具备 2MB 的 L2 缓存。Redwood Cove 在指令缓存和微架构细节上延续了此前的改良,同时面向服务器平台恢复并强化了 AVX-512 支持(双 512-bit FMA 单元)与 AMX 指令集,这使得在向量和矩阵工作负载下每核的执行通路具备很强的吞吐能力。 缓存与延迟的实际测量揭示了 Xeon 6 的一些显著特点。Redwood Cove 的核心私有缓存延迟与客户端版本相近,L1D 延迟为 5 个周期,L2 为 16 个周期。
不同之处在于 L3 缓存的组织方式与延迟表现。Xeon 6 提供了一个大容量的 L3 池,测试机型在 120 个 CHA(Caching/Home Agent)实例下合计约 480MB 的 L3,但每核可用的 L3 份额仍然非常可观。单次 L3 命中延迟约为 33ns(约 130 个周期),比某些上一代设计略为增加。更重要的是,L3 命中延迟随着跨 die 访问会显著上升:跨一个 die 边界的 L3 访问会增加约 24ns,跨两道边界则接近 80ns 左右。这意味着在默认的多 NUMA 划分下,非本地资源访问会对延迟造成明显影响。 内存控制器的布局对 DRAM 访问延迟和带宽也至关重要。
Xeon 6 的高端 SKU 在每个计算 die 上放置 DRAM 控制器,最大的配置是 12 条内存通道(每个 compute die 四条),AWS 的实例配备了 Micron DDR5-7200,总容量达到每插槽 1.5TB。Xeon 6 默认启用 SNC3(sub-NUMA clustering,3 路子 NUMA)模式,将整个物理地址空间划分为三个 NUMA 节点,每个节点与对应计算 die 上的 L3 与内存控制器绑定。这种划分有助于保持内存访问亲和性并降低在本地 NUMA 内的访问延迟,但代价是跨 NUMA 访问的远端惩罚更为显著。 实际测得的 DRAM 延迟与带宽数据可以直接反映这些设计权衡。以本地 NUMA 节点内的访问为基准,跨越一个 die 边界访问远端的 DRAM 会将延迟提高到约 157.44ns,比访问本地控制器大约多出 26ns;跨两道边界延迟接近 181.54ns。相较之下,AMD 基于 Zen 5 的 Turin 平台在测试中显示出约 125.6ns 的内存延迟,显得更为低延迟,即便该 AMD 系统已启用将访问分散于所有内存控制器的 NPS1 模式。
带宽方面,Xeon 6 在单核层级展现出较强的缓存层吞吐能力:每核心的 L3 读取带宽接近 30GB/s,单核的 DRAM 带宽略低于 20GB/s。由于 Xeon 6 提供了极大的共享 L3 容量,这种带宽与吞吐的配置往往适合高并发、对吞吐有要求且数据局部性较好的服务器工作负载。扩大到整芯片,作者在遵循 NUMA 亲和的前提下测得的总 DRAM 带宽约为 691.62GB/s,远高于 Emerald Rapids 在类似测试下的 323.45GB/s,并且优于当时测得的一台 EPYC 9355P(DDR5-5200)在统一 NUMA 下约 478.98GB/s 的表现。Xeon 6 在带宽扩展上以更多的内存通道和更快的 DRAM 频率获得了显著优势。 但带宽与延迟往往并非单向受益:Xeon 6 的大容量 L3 带来的是更高的平均命中容量,但 L3 的绝对访问延迟比某些竞争对手更高。与 AMD 的 Zen 5 相比,AMD 采用更小但更高性能的 L3 实例(每 8 核一个 L3 大块),因此在 L3 延迟与单核 DRAM 带宽上可能更占优势,尤其是在低线程或对延迟敏感的工作负载下。
Intel 的策略是通过较大的共享缓存来减少对 DRAM 的直接依赖,从而在吞吐型负载中体现优势,但当访问必须穿越片间边界时的惩罚仍然显著。 片间互连与一致性协议是决定性因素之一。Xeon 6 采用 mesh 互连,CHA 作为缓存与内存一致性控制单元,并通过一致性哈希(consistent hashing)把物理地址路由到相应的 L3 切片。观察表明,Xeon 6 更倾向于把每个 NUMA 节点的物理地址映射到该节点所属 die 的 L3 切片,这意味着远端 NUMA 的数据通常只会被远端的 L3 缓存所缓存,从而清晰分隔了缓存责任域。这种策略在局部性高的场景下有利,但也放大了跨 NUMA/跨 die 访问时的延迟和一致性开销。 核心间的缓存一致性延迟测试显示,两个核心在同一 compute die 内传递数据的往返延迟大多落在 50-80ns 范围。
跨 die 的情况下延迟会略有上升,但总体仍然保持在可控范围内,最坏情况在通过最远 CHA 时接近 100-120ns。相比之下,某些 AMD 服务器平台在穿越集群边界时的类似延迟达到 150-180ns,表明在核心对核心通信延迟方面,Intel 的"逻辑单片"策略仍保有一定优势。 在微基准之外的实际应用表现上,单线程的 SPEC CPU2017 测试显示这一 96 核 Xeon 6 型号在单核性能上还落后于设计上更注重单核性能的低核数处理器。这与其面向高并发与高吞吐的产品定位相符。与 AWS 的 Graviton 4 进行了对比,Xeon 6 在整数运算方面接近 Graviton 4 的表现,在浮点运算上则领先约 8.4%,这反映出在向量扩展(如 AVX-512/AMX)可被有效利用的场景下,Xeon 6 的架构优势能够体现出来。 对系统部署与软件层面的启示值得关注。
首先,Xeon 6 在默认的 SNC3 模式下更强调 NUMA 亲和性管理。对于延迟敏感或频繁需要跨 NUMA 访问的数据结构,应用应当尽量保证线程与数据的内在亲和关系,避免在运行时触发大量跨 die 的 L3 或 DRAM 访问。对 JVM、数据库缓冲池、分布式缓存等需要精细内存管理的系统而言,显式绑定线程/内存或调整分配策略能带来明显的性能改进。其次,对于高度并行并追求最大带宽的批处理或流式计算任务,Xeon 6 的大量内存通道与高速 L1/L2 将带来显著优势,只要数据局部性得到保证。 从体系结构演进的视角来看,Intel 与 AMD 采取了两条不同路线。Intel 追求逻辑上尽可能单片化的视觉体验,试图通过扩展 mesh 与 CHA 的规模来维持统一的缓存一致性语义;AMD 则通过分层互连(每个 CCD 内部的高速 L3,再由 Infinity Fabric 处理较慢的全局流量)减少了对高密度片间互连的依赖,从而在延迟控制与模块化扩展间找到了一种平衡。
两者各有优势:Intel 在缓存容量与内核到内核延迟方面有潜在优势,而 AMD 在每次访问的低延迟和局部 L3 性能上更有竞争力。 未来道路上,工程问题依旧会围绕互连密度、片间延迟以及如何在保持可扩展性的同时控制一致性成本。社区讨论与厂商演示提出的思路包括通过堆叠与更多的金属层来改善片间信号路由,或采用多层次缓存结构(例如将 L3 划分为更小的低延迟分区,并引入 L4 或更大容量的共享层以平衡一致性)。Intel 自身也在后续版本的核心与封装上持续迭代,包括新一代内核以及不同的 chiplet 堆栈策略,期待在保持高吞吐的同时进一步缩短跨 die 延迟。 总结来看,Xeon 6 在内存子系统上的设计充分体现了为云与数据中心级别吞吐扩展而做出的权衡:通过更多的内存通道、快频 DDR5 和大容量共享 L3 获取可观的整体带宽与缓存容量,同时在互连与跨 die 延迟上付出代价。对于追求吞吐和大内存工作集的应用,它有明确优势;对于对延迟极度敏感或需要频繁跨 NUMA 访问的任务,则需通过软件层面的亲和性调优或选择不同的配置模式来避免性能下滑。
随着厂商在物理封装和互连设计上的进一步投入,未来几代产品可能在缩短片间延迟与提高互连带宽方面带来更多改进,但目前在部署与调优层面,理解 Xeon 6 的 NUMA 特性与缓存行为依然是获得最佳性能的关键。 。









