Kafka Streams作为Apache Kafka生态系统中的流处理库,以其简洁的接口和强大的功能,在实时数据处理领域备受关注。它不仅简化了复杂的流数据计算,还通过高效的设计保障了系统的可伸缩性和容错能力。深入探索Kafka Streams的内部结构与运行机制,有助于开发者更好地设计和优化流处理应用,提升系统性能和稳定性。 Kafka Streams诞生的背景源于现代数据应用对流式算力的强烈需求。数据流动从单点传输发展为链式处理,消息需要经过多步转换、聚合、过滤及关联计算,传统的单线性处理方式难以满足高吞吐量和低延迟的要求。Kafka Streams以库的形式直接嵌入Java应用中,无需单独集群部署,大幅降低了使用门槛。
它通过定义明确的数据流拓扑结构,为复杂处理流水线提供统一的抽象和分布式运行时支持,极大提升了开发体验和执行效率。 流处理的核心在于数据管道的搭建,Kafka Streams以有向无环图(DAG)方式组织拓扑节点,节点根据功能分为源节点、处理节点和汇节点。源节点负责从Kafka主题读取消息并反序列化,处理节点承担业务逻辑转换,可能涉及无状态和有状态的运算,如过滤、映射、聚合等。而汇节点则将处理结果序列化后写入目标Kafka主题。节点间通过递归调用process方法和forward机制实现数据传递,形成稳定且灵活的流动路径。 Kafka Streams为开发者提供两种构建拓扑的主要方式:基础的Processor API和上层的DSL。
Processor API允许用户直接控制每条消息的处理细节,包括访问上下文、状态存储和调度行为,适合定制化处理需求。DSL则封装了常用算子,如连接、分组、计数与窗口操作,允许以声明式方式编写流处理逻辑,极大简化了开发过程。无论采用哪种方式,最终都会编译成统一的拓扑结构执行,保证一致的执行语义和容错能力。 状态存储是Kafka Streams实现有状态流处理的关键。它提供了一套KeyValueStore接口,支持本地持久化和查询。内存型存储基于Java TreeMap实现,适合轻量级场景;而基于RocksDB的实现则支持大规模数据存储,具备优越的读写性能和故障恢复能力。
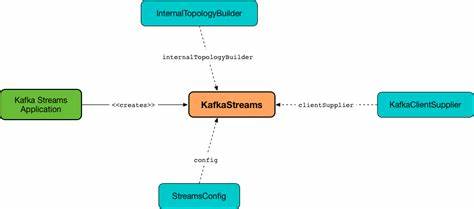
状态存储的数据通过变更日志主题进行持久化和复制,当实例发生故障时,其他实例可从日志恢复状态,保证处理的连续性和准确性。 运行模型上,Kafka Streams作为嵌入式库存在,允许多个实例通过共享application.id实现协作,每个实例包含一个或多个StreamThread,线程内部管理若干任务(Task)。每个任务对应若干主题分区,用于处理具体的数据分片。分区到任务、任务到线程及线程到实例的映射关系保证了负载均衡和高并发处理能力。Kafka的消费者组协议与自定义的StreamsPartitionAssignor协同工作,实现了动态分区分配和故障迁移,从而确保系统的横向扩展和弹性恢复。 StreamThread作为Kafka Streams内核执行单元,负责消费数据、恢复状态、处理消息和提交偏移量。
它维护消费者客户端,调度任务管理器调用对应拓扑节点的处理方法。线程不断通过轮询Kafka,拉取消息并分发给对应任务。每个任务在接收到消息后,会按拓扑定义的路径依次调用各处理节点,最终生成结果并提交。此外,线程还管理周期性操作,如触发打点函数,执行状态提交和清理历史状态,保障计算的实时性和稳定性。 任务管理器(TaskManager)在StreamThread中扮演协调者角色,管理任务的生命周期,包括创建、恢复、调度和销毁。每当有新的分区分配,TaskManager会生成对应的StreamTask,并负责数据缓存、状态恢复和变更日志同步。
它确保任务按正确顺序处理数据,避免乱序带来的数据不一致问题。这种严密的协调机制是Kafka Streams能够在复杂分布式环境下保持数据准确和服务可靠的根基。 Kafka Streams的设计充分考虑了扩展性和容错性。通过分布式消费者组协议,多个应用实例自动协作,实现对整个数据流的消费和处理。当实例失效或新实例加入时,重新分配分区,确保所有数据被有效处理。状态通过变更日志远程备份,本地状态目录支持自动清理,减少存储冗余。
管理组件如全局线程(GlobalStreamThread)用于维护全局状态存储,保证跨分区和跨实例的一致视图。 实际应用中,Kafka Streams可以灵活应对各种业务需求,从最简单的单词计数,到复杂的事件驱动转换与关联分析。其内置的窗口处理允许按时间或事件定义业务逻辑,支持水位线和出发策略,满足实时计算的严格时序要求。无论是金融风控、物联网数据处理,还是实时推荐和指标监控,Kafka Streams都提供了稳定且高效的流处理能力。 总体来看,Kafka Streams不仅是一个开发快捷的流处理库,更是一套全面的流式计算引擎,其内部架构在性能与灵活性之间取得了优雅的平衡。通过源节点的消息获取、处理节点的丰富算子支持、状态存储的高效持久化、线程与任务的协调运行,以及消费者组的智能分配,它实现了高吞吐量、低延迟、强容错的流处理应用。
了解Kafka Streams底层的设计理念和具体实现细节,有助于开发者优化程序性能,合理配置运行参数,定位异常状况。同时,这也为构建稳定可靠的实时数据平台提供了坚实基础,是现代大数据处理技术不可或缺的重要组成部分。随着流数据应用场景不断扩展,Kafka Streams无疑将继续发挥其核心作用,引领实时计算的发展方向。