随着GPU加速技术在现代计算中的广泛应用,尤其是在人工智能、机器学习、高性能计算以及游戏等领域,如何高效地实现GPU应用的状态保存与恢复成为核心挑战。Checkpoint/Restore技术因其能够捕捉进程状态并实现快速复原,被广泛应用于容错、高可用和实时迁移等场景。然而,传统的Checkpoint/Restore技术在处理GPU相关状态时面临复杂性和效率瓶颈。本文将聚焦于用户态进程Checkoint/Restore工具CRIU(Checkpoint/Restore In Userspace)在GPU恢复阶段的创新设计,尤其是AMD GPU插件引入的并行恢复路径,带来恢复效率的大幅提升,并探讨其背后的技术细节与未来潜力。 Checkpoint/Restore的基本理念是将进程的运行状态完整地保存为快照,使得该进程能够在之后的任意时刻,在原有环境或新的环境中准确恢复,并继续运行。这一过程精细地记录内存数据、文件描述符、CPU寄存器状态等重要信息。
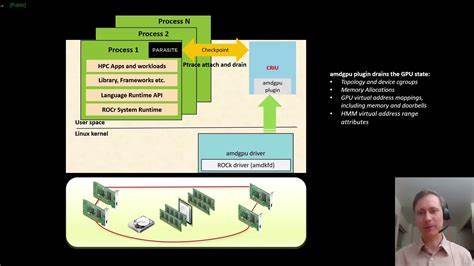
尽管这一过程在CPU计算任务中已趋成熟,GPU加速应用却因GPU内部状态的多样且复杂、厂商落实的驱动结构各异等因素,导致恢复实施难度大幅增加,性能瓶颈尤为突出。 CRIU作为Linux生态中领先的用户态Checkpoint/Restore框架,以其灵活的插件机制在GPU管理领域获得广泛关注。不同GPU厂商推出的插件弥补了GPU状态恢复回归的复杂性差异,例如AMD通过AMDGPU插件处理其GPU状态和显存的保存与重载,NVIDIA也拥有相应支持。这些插件通过CRIU定义的钩子函数(Hooks)在关键恢复步骤中介入,实现对驱动状态及显存等专有资源的定制化管理。 传统的AMDGPU插件在恢复阶段的核心流程是由CRIU恢复子进程逐步完成,其中包括文件描述符的恢复、驱动状态调用(如ioctl指令)、以及显存内容通过系统DMA传输的重建。然后紧接着,CRIU恢复子进程会进行主机内存的卸载和重加载,这一步骤需要解除原有映射、安装新映射,过程中会调用独立的“restore blob”,一段安全且独立的代码处理内存映射,保证恢复操作的稳定性和完整性。
虽然流程严谨,但关键瓶颈在于显存恢复和主机内存恢复必须顺序进行,且均由单线程完成,大大限制了恢复速度和并行效率。 尝试通过线程并行提升性能的直观方案遭遇技术阻碍。主机内存恢复需要卸载当前内存映射,包括GPU恢复线程依赖的库,导致内存访问冲突和程序异常,限制了简单线程并行的可行性。针对这一问题,上海交通大学的研究团队提出并实现了基于CRIU核心的POST_FORKING新钩子机制,将GPU显存数据恢复职责从恢复子进程转移至主CRIU进程,并通过进程间文件描述符传递实现两阶段并行恢复,显著优化了整体性能。 该方案的关键技术基石是利用DMA-BUF机制实现GPU显存的跨进程共享。AMDGPU驱动中显存通过“缓冲区对象”管理,这些对象支持导出为DMA-BUF文件描述符。
通过Unix域套接字,恢复子进程可以将这些文件描述符及相关命令发送给主CRIU进程。主进程则借助该机制在后台线程中导入缓冲区对象,使用系统DMA完成GPU显存内容的恢复。与此同时,恢复子进程自身不再负责显存读取和写入操作,得以专注于主机内存的复杂恢复任务,从而实现两阶段任务的高效并行。 具体来看,AMDGPU插件对原有钩子函数amdgpu_plugin_restore_file的大幅改造,使其由执行全流程恢复转向缓冲区对象扫描和文件描述符传送。POST_FORKING钩子新增了amdgpu_plugin_post_forking函数,在主进程中初始化后台恢复线程并维护跨进程通信套接字,保障恢复指令的及时接收和显存恢复的稳健执行。同步点设计体现在amdgpu_plugin_resume_devices_late函数,该步骤确保子进程的内存恢复完成后,主进程后台线程同步结束显存数据的恢复,完成并行过程的协调。
这一策略带来的性能改进显著,实验结果显示,在测试平台上当数据驻留于页面缓存时,整体恢复时间缩短约34.3%;即使是在从磁盘读取数据恢复的场景下,也实现了7.6%的恢复时间优化。该突破提高了GPU应用的容错恢复能力和系统迁移效率,对实时计算和高可用性服务尤为关键。 GPU加速应用的Checkpoint/Restore技术仍处在积极发展阶段,除AMD GPU外,不同GPU厂商的驱动架构差异和闭源限制带来了挑战。持续推进CRIU社区与各GPU厂商的合作,是实现跨平台、跨架构、高效GPU状态保存恢复的关键路径。随着云计算、边缘计算和人工智能负载的发展,对快速恢复和实时迁移的需求只会愈发强烈,基于并行恢复技术的创新将不断加速。 未来,进一步细化内存管理策略、扩展多GPU及多进程环境的支持,以及集成更丰富的图形栈环境支持(如Wayland、X11客户端的状态管理)将成为重要方向。
与此同时,安全性和一致性保障仍是设计和实现中的重点,确保恢复过程中的数据完整和系统稳定至关重要。 综上,CRIU引入的GPU恢复并行路径创新不仅增强了GPU加速应用的Checkpoint/Restore能力,更为用户态进程迁移和容错机制提供了坚实的技术基础。借助DMA-BUF文件描述符传输机制和精细设计的钩子函数,显存与主机内存恢复任务实现了有效解耦与并行处理,恢复效率大为提高。随着GPU应用的持续增长,这一并行恢复架构必将在Linux生态中发挥越来越重要的作用,推动系统软件与硬件协同创新迈向新高度。