随着人工智能技术的快速发展,检索增强生成技术(RAG,Retrieval-Augmented Generation)作为连接大型语言模型与知识库的重要桥梁,正受到越来越多企业和开发者的关注。RAG的核心优势在于通过检索相关知识片段,为生成式模型提供准确的上下文支持,显著提升回答的准确性和知识覆盖率。然而,RAG在保证信息精确的同时,也面临着延迟带来的性能瓶颈,尤其是在处理大型知识库和多轮对话时,如何平衡速度与准确性成为技术优化的重点。本文将详细探讨一种革命性的优化方案,成功将RAG系统的处理速度提高了50%,并阐述这一突破为智能对话系统带来的深远影响。 RAG技术背景及其性能挑战 RAG技术通过在生成模型进行回答前先进行相关信息的检索,避免模型对超大知识库的依赖,降低了生成时的搜索空间,保证了回答内容的准确性和时效性。在实际应用中,尤其是企业级服务,知识库规模往往庞大且动态更新,RAG能够根据当前对话上下文快速定位最相关的信息片段,为模型提供高质量提示,提升用户体验。
然而,要实现这样高水平的检索与生成协同,系统必须在极短时间内完成对用户查询的理解、检索结果的定位以及文本生成,这对端到端的响应速度提出了严苛要求。传统的RAG实现方式中,查询重写(query rewriting)步骤常因依赖外部大型语言模型而成为性能瓶颈,导致整体响应延迟显著增加,影响用户的实时交互感受。 深入理解查询重写的性能瓶颈 用户在多轮对话中往往会使用模糊或依赖上下文的表达,例如"这些限制可以按流量模式自定义吗?"这类问题需要系统具备将对话历史浓缩成明确且上下文独立的查询能力,才能顺利检索相关知识。 查询重写正是为解决这一需求而设计,通过调用语言模型,将模糊指代和上下文依赖转化为精确且自包含的检索查询,极大提升了检索的相关度与后续生成的准确性。 然而,这一步骤如果仅依赖单一的外部API接口,尤其是大规模语言模型,往往会受制于该服务的响应速度和稳定性,导致查询重写成为在线服务的主要延迟来源。在实际监控中发现,查询重写的延迟占据RAG整个流程高达80%的比例,成为优化关键。
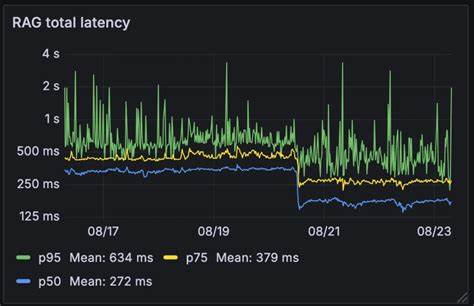
创新方案:多模型竞赛加速查询重写 为解决这一难题,团队设计并实现了基于"模型竞赛"(model racing)的全新查询重写架构。在这一方案中,同一查询会并行发送到多个性能各异但均具竞答能力的模型,包括自托管的Qwen系列模型(3-4B及3-30B-A3B参数规模)。这一策略极大提升了查询重写环节的响应效率。 多模型同时作答的机制,如同竞赛一般,让最快返回有效查询结果的模型胜出,系统立即采用其输出继续后续检索流程。 这一方式有效规避了单一模型响应迟缓或不稳定带来的风险,并通过引入超时机制,在所有模型均未及时响应时,将用户原始请求作为备选查询继续流程,防止对话中断或卡顿,确保整体交互的流畅性。 性能提升与系统稳定性的深远影响 经过优化,系统的中位延迟从原先的326毫秒大幅缩短到155毫秒,降低幅度超过50%,在75分位和95分位延迟上也有显著下降,分别从436毫秒和629毫秒降低到250毫秒和426毫秒。
这一切意味着RAG能够实现在每一次用户查询时调用无感察的实时检索,几乎不产生影响体验的额外延迟。 另外,多模型竞赛方法的引入极大提升了系统的鲁棒性。在先前依赖第三方模型时,外部服务的波动和宕机曾对对话连续性构成威胁。而现有架构利用内置多模型备份,能够在外部模型不可用时无缝切换,保证业务不中断。 此外,基于自有计算资源的推理服务,额外计算开销被有效控制,与外部API调用的计费方式相比,大幅降低云端成本,提升了方案的经济性和可持续运行能力。 技术优化背后的价值与未来展望 子200毫秒级的查询重写延迟,意味着RAG不再是实时对话系统的瓶颈。
智能代理能够持续保持上下文感知和高响应速度,无论是面对海量企业知识库还是复杂交互场景,都能提供顺畅体验。 降低延迟不仅提升用户满意度,还为企业大规模部署RAG技术奠定基础,尤其是在金融、电信、医疗等对时效要求极高的领域中,快速响应与精准知识支持成为赢得用户信任的关键。 随着模型架构不断进化,未来查询重写将有望引入更多自适应机制,动态选择最合适的模型组合进行竞赛,进一步压缩响应时间。同时,结合更多边缘计算节点,可以实现地理位置优化,减小网络传输带来的时延。 结语 对于追求极致性能与精准交互的智能对话系统而言,通过多模型竞赛优化查询重写,成功将RAG整体速度提升一倍,是技术进步的重要里程碑。这种架构不仅带来了显著的延迟减少,更提升了系统的稳定性与成本效率,为构建未来智能服务提供了坚实基础。
不断改进的检索增强生成技术,将继续推动人工智能在企业及日常生活中的更广泛落地,实现更智慧、更高效的交互新时代。 。