近年来,文本转语音技术(Text-to-Speech,简称TTS)经历了飞速的发展,从单一简短的语音合成逐步迈向更复杂、更自然的长文本、多说话人语音内容生产。作为该领域的前沿模型,微软推出的VibeVoice,展现出了颠覆性的技术优势和应用潜力。VibeVoice不仅是一个开源框架,更是一次对现有TTS系统在表达力、计算效率和多说话人支持层面的重大突破。VibeVoice诞生的背景,离不开行业长期面临的几个挑战点。传统TTS模型大多受限于处理长度短、说话人数量有限以及在情感自然表达上的不足,难以应对现代复杂的多说话人对话和长时间语音生成需求。微软针对这些问题,设计出基于连续语音标记器的超低帧率处理机制,并结合大型语言模型(LLM)强化文本语境理解,全面优化了长对话文本合成的质量和效率。
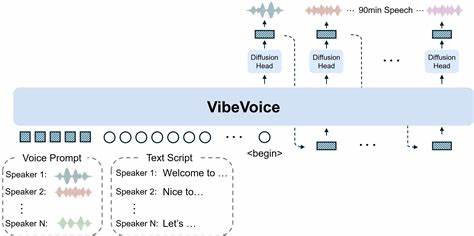
核心技术之一的连续语音标记器,是VibeVoice效率提升的关键。这种标记器以7.5赫兹的超低帧率对音频进行抽象表达,显著减少了序列长度,既保留了高音频保真度,也大幅降低了算力开销。它将语音信号分解为声学和语义两类标签,形成对音频全方位的语义和声学描述,有效保障语音的自然度和说话人一致性。结合下一词生成的扩散(diffusion)框架,VibeVoice借助大型语言模型来捕捉对话文本的语境和逻辑流动,扩散头则负责生成高保真的声学细节,使得整个合成过程既智能又具非常好的灵活性。与许多现有模型只能支持1至2个说话人的限制不同,VibeVoice可支持多达4个不同的说话人协同参与,实现超过90分钟的长对话语音生成。这为播客、访谈、对话式内容创作、跨语言对话及多角色场景语音提供了强大工具。
此外,VibeVoice具备强大的情感表达能力。它不仅能够准确传达基于上下文的情绪变化,还支持即兴演唱和背景音乐混合,提升了语音内容的感染力和聆听体验。在跨语言合成方面,VibeVoice亦展现出良好适应性,实现了如普通话到英语的自然转换,打破了语言壁垒,方便国际化内容的生产和传播。微软基于负责任的AI使用原则,在发现部分用户的误用行为后,暂时关闭了VibeVoice的开源仓库,体现了其对技术安全和伦理的高度重视。该举措旨在营造健康的开发与应用环境,确保此开源模型推动的是积极、合法且有益的技术创新。行业专家和开发者普遍认为,VibeVoice的架构突破了传统TTS在可扩展性和连续语音合成上的瓶颈,尤其在高质量、多角色长篇内容生成领域具备巨大商用前景。
未来,随着开源生态的完善和社区协作的深入,VibeVoice有望成为引领新一代语音合成技术的标杆。展望未来,VibeVoice的技术创新还可能为教育、娱乐、智能助理及多模态交互等领域带来深远的影响。通过更加自然、生动且具个性化的语音输出,提升人机交互体验的真实感和亲和力。同时,持续优化的计算效率也令语音合成服务更具成本竞争力,更容易普及到移动设备和边缘计算场景中。总结而言,微软VibeVoice不仅是技术上的一次重要飞跃,更是对未来智能语音交互形态的积极探索。它通过先进的多说话人长文本音频生成技术,将人工智能语音服务推向了更高层次,让内容创作者和最终用户都能享受到更加丰富和自然的语音交互体验。
随着语音合成技术与大语言模型等人工智能工具的深度融合,VibeVoice彰显了开源创新在推动行业进步中的巨大力量。相信未来这项技术将助力更多创新应用,驱动人类沟通方式的持续变革,走入更加智能和多元的语音交互新时代。 。