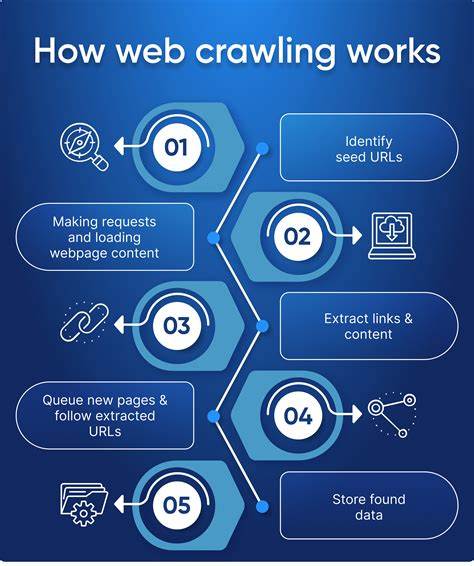
随着互联网的飞速发展,网页内容日益丰富且规模庞大,如何高效快速地抓取海量网页数据已成为技术圈关注的热点。2025年,一场抓取十亿网页,仅用时略超过24小时的技术实验引发了广泛讨论,揭示了当前网络爬虫捕获网页规模与速度的最新极限与实现路径。本文将带您深入了解这场技术突破的背景、设计理念、实施细节及关键机遇与挑战。多年来,网页抓取技术持续演进,从最初依赖简单蜘蛛程序,到今天依赖异步并发、内存数据库和高性能计算架构的综合系统。在这次突破中,设计者放弃了传统的分散式模块方案,转而采用紧凑、高度整合的独立节点集群,每个节点实现抓取、解析和数据存储全栈功能,分片处理特定域名集合。选择在有限预算下最大化单机性能,是这一设计的核心驱动力,也体现了技术革新如何与成本效益紧密结合。
节点选用了支持NVMe固态硬盘和高速10Gbps网络接口的高性能云实例,配合单实例内运行的Redis数据库作为爬取状态管理中心,实现快速高效的数据存取。高并发异步抓取进程充分利用多核CPU核心,将请求并发数提升至6000多个,显著最大化网络与计算资源利用率。除了网络带宽充裕,令人意外的是CPU反而成为瓶颈。分析指出,SSL握手验证占用了约四分之一的CPU时间,反映出如今绝大多数网站均采用HTTPS访问,而SSL安全协议的计算开销对爬虫性能有着深远影响。解析环节同样呈现挑战,现代网页愈发臃肿,平均HTML页面大小较2012年翻倍增长。常用解析库已难以满足高效需求,设计者采取了针对HTML5的高效解析引擎selectolax替代传统lxml,大幅提升解析效率。
另外,截取页面内容至250KB的策略在保障内容完整性的同时,降低了CPU解析压力。这次抓取严格遵守网络礼仪,遵循robots.txt协议,对热门且易受影响的小型网站设置爬取间隔,避免给目标服务器带来过重负担。这不仅体现了负责任的网络爬虫文化,也保证了爬取过程中较低的错误率和系统稳定性。系统实现了基本的容错机制,支持在崩溃或中断后恢复爬取,尽管部分状态数据可能丢失,但整体抓取任务仍能平稳完成,体现对外界不确定因素的妥善应对。在实际运行中,单节点同时运行若干解析及抓取进程,达成约950页面每秒的处理速率,整体现代化集群由12节点组成,总计完成超过十亿页面的抓取,总时长约25.5小时,成本仅约462美元,较十年前数万美元的项目预算实现了质的飞跃。运行中也遭遇超大域名链接数量导致内存飙升的意外问题。
部分热门网站如yahoo.com和wikipedia.org的前端链接数量巨大,导致部分节点内存负载异常,迫使设计者动态调整任务排期及手动排除少数异常域,保障整体任务顺利推进。这一探索也给业界启示,未来网页内容的动态化和JavaScript执行的重要性日益凸显。由于此次抓取仅抓取静态HTML内容,未执行任何JavaScript,未来大规模抓取需突破动态页面渲染障碍,技术难度将大幅提升,成本压力同样攀升。当前使用的异步协程编程模式,为实现高并发下的CPU和网络资源复用提供了坚实支撑。该模式避免频繁的上下文切换,优化了系统响应速度和吞吐量,这也标志着现代爬虫设计从单纯的IO并发向综合资源优化的转变。项目还印证了现代云计算平台弹性存储的重要性。
相比使用云对象存储(如S3)需为存储时间和请求次数付费,使用本地实例存储可大幅节约短期大规模数据存储成本,权衡成本与耐久性是设计关键。此次成功实现了对亿级网页的高效抓取,验证了现代硬件结合高性能软件的潜力,为后续大规模互联网数据采集和分析提供了技术基石。对研究者和行业从业者而言,这一项目不仅呈现了网络爬虫技术的最新水平,更在成本和时间效率上为大规模数据抓取设定了新标杆。展望未来,网络爬虫需不断适应动态网页加重、加密协议普及及网络安全机制升级带来的多重压力。传统的纯HTML爬取将逐步被更复杂的页面渲染技术所替代,相应的计算资源需求和技术难度也将提升。爬取过程中必须兼顾速度与网络伦理,尊重网站设置,避免侵害他人利益,这对行业健康发展至关重要。
诸多云服务商和开源社区正在加快步伐,推动开发更高效的解析器、优化异步网络库、研发支持JavaScript执行环境的爬虫框架,力求在保证抓取深度和质量的同时,降低成本和运维复杂度。整体来看,2025年的十亿网页24小时抓取实验不只是对技术的测试,更是一次对互联网生态理解和尊重的体现。它昭示着未来数据驱动应用愈加依赖高效、大规模数据获取的趋势,同时也提醒我们注意技术进步带来的伦理和规范挑战。在未来,融合智能化算法的爬虫将可能实现更智能的网页识别与抓取策略,随着AI与自然语言处理能力的发展,网页内容分析将更为精准,助力数据挖掘和知识图谱构建,激发更多创新应用,推动数字经济迈上新台阶。