随着人工智能技术的迅猛发展,大型语言模型(LLMs)在多个领域展现出了令人瞩目的能力。特别是在化学科学领域,LLMs的应用引发了研究人员和业界的广泛关注。本文围绕大型语言模型与化学专家在化学知识和推理能力上的对比展开,分析其优势、局限,并展望未来人工智能在化学领域的潜力。 大型语言模型是基于深度学习技术训练的机器学习模型,它们通过海量的文本数据学习语言模式,能够理解并生成高度复杂的自然语言内容。近年来,随着模型规模的扩大和训练数据的丰富,LLMs在回答化学相关问题、设计化学反应、预测分子性质等任务中表现出了日益卓越的能力。一些最先进的模型甚至在特定化学测验中超越了多数人类化学家的表现。
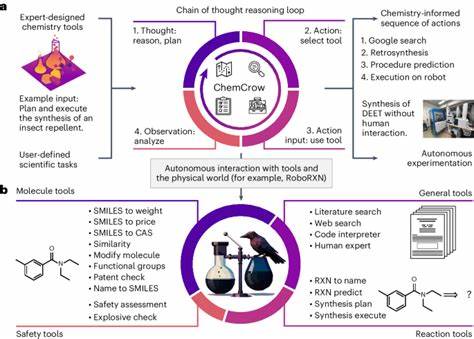
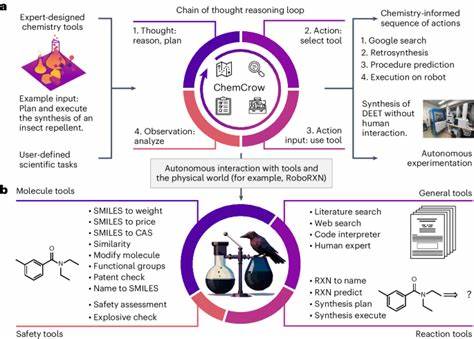
然而,LLMs与传统化学专家之间仍存在显著差异。人类化学家不仅依赖知识积累,更注重实验经验、直觉判断和跨学科的综合推理能力。LLMs虽然能快速访问庞大的文本信息库,但在深层化学推理和理解分子特性结构的能力方面仍有不足。此外,LLMs的回答有时会表现出过度自信,导致错误信息的传播。 为科学有效评价LLMs在化学领域的表现,最近出现了名为ChemBench的自动化评估框架。该框架汇集了2700多个涵盖化学各个分支的问答对,涵盖基础知识、复杂推理、计算和化学直觉等多种能力。
通过该平台,研究人员能够系统地测试不同LLMs在广泛化学任务下的表现,并将其与化学专家的表现进行对比。 研究表明,顶尖的LLMs平均表现优于参与测试的人类化学专家,尤其在标准化考试题或知识性问题上表现突出。然而,在涉及实验推理、分子结构分析及安全性判断等领域,模型的表现仍远低于人类专家。例如,对于核磁共振信号数预测等需要分子对称性和拓扑结构推理的问题,模型准确率显著下降,这反映了其在分子结构理解上的局限。 此外,LLMs在判断化学偏好和“化学直觉”方面也表现欠佳。从药物设计的角度来看,化学家的分子偏好往往基于多年的实践和经验,具有较强的主观性和灵活性。
当前模型在模拟这种偏好时,表现过程接近随机,显示出一种认知盲区和潜在的优化方向。 置信度估计是衡量模型可靠性的重要指标。实验发现,许多LLMs自我评估回答正确性的置信度常与实际表现不符,存在明显的误判现象。某些问题上,错误回答的置信度甚至高于正确回答,这对实际应用带来了风险,特别是在涉及化学安全和毒性评估方面。因此,如何增强模型的自我校验与不确定性识别能力成为亟待解决的关键技术挑战。 面向未来,LLMs在化学领域的应用前景广阔。
通过不断优化训练数据、引入专业数据库、扩展跨模态能力(如结合图像与结构数据)、以及精进与实验设备的协同,人工智能有望成为化学家得力的“数字助手”,在实验设计、数据整理与新材料发现等环节发挥重要作用。 值得注意的是,随着LLMs能力的提升,化学教育也面临转型。传统侧重于记忆和重复操作的教学模式可能逐渐被基于批判性思维和综合推理的新方法替代。学生和研究人员需要掌握如何有效利用人工智能工具,同时保持对实验与理论的深入理解和判断能力。 同时,LLMs的发展也伴随着伦理和安全隐患。技术滥用有可能用于设计危险化学品或武器,因此开发者和监管机构需要建立严格的监管机制,确保技术造福社会而非被滥用。
总结来看,大型语言模型在化学知识和推理方面展现出令人惊叹的潜力和一定的超越性,但其仍难以完全取代人类专家在复杂推理、实验操作及直觉判断中的独特优势。伴随评估工具如ChemBench的不断完善,未来化学人工智能的安全、有效和专业化发展道路愈加清晰。为实现化学研究和教育的创新突破,人机协作的模式将成为新的主流,人工智能辅助化学家开启前所未有的科学发现时代。