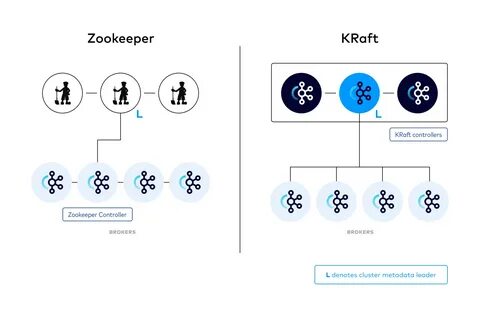
Apache Kafka作为现代流数据处理和消息系统的中坚力量,一直以来备受开发者和企业用户青睐。随着分布式系统复杂性的不断增长,Kafka的元数据管理和集群一致性问题愈发突出。传统上,Kafka依赖外部的ZooKeeper进行集群协调和元数据存储,但ZooKeeper的依赖带来了额外的运维复杂性、性能瓶颈以及状态不一致的风险。为了应对这些挑战,Apache Kafka从4.0版本开始引入了基于Raft协议的KRaft协议,彻底革新了其元数据管理架构,替代了ZooKeeper,打造了一个高度自管理、可扩展且安全的元数据管理机制。 理解KRaft协议的核心,首先需要认识Raft这一经典的共识算法。Raft通过领导选举、日志复制以及安全规则,将分布式一致性问题拆解成易于理解和实现的模块。
它保证了在网络分区或部分节点故障的情况下,只要大多数节点存活且互联,系统依然能够正确运行且数据保持一致。Kafka选用Raft作为其控制层一致性的基础,正是基于Raft在分布式系统领域的广泛验证和成熟表现。 KRaft协议的最大创新之处在于引入了控制器节点角色,形成了控制器池。控制器节点间通过Raft算法选举出领导者,后者负责处理集群元数据的写入与复制,保证各控制器节点状态同步。Kafka Broker节点则作为观察者角色,向控制器注册并获得最新的集群配置信息,但它们不参与控制层的选举和元数据一致性决策。这种设计有效将数据平面与控制平面解耦,同时提升了系统整体的鲁棒性和扩展能力。
除了控制器角色的引入,KRaft协议的实现基于单线程事件驱动模型,确保控制器的操作顺序一致,简化了内部状态管理。通过KafkaRaftClient,控制器节点实现了Raft算法中的Leader选举和元数据日志的顺序复制。该客户端通过轮询机制与其他控制器通信进行元数据拉取,这种拉取式(pull-based)的复制策略,缓解了领导者维护大量连接的负担,提升了网络资源利用率和扩展性。 元数据管理方面,KRaft协议采用了专用的内部主题__cluster_metadata,存储所有元数据变更的日志。该主题仅含单分区,为序列化元数据变更操作提供保证,并通过周期性快照机制控制日志大小,防止磁盘占用无限膨胀。新的元数据版本控制系统确保所有节点支持一致的特性集合和协议版本,为Kafka今后的功能迭代和兼容性提供坚实基础。
在安全性与一致性保障层面,KRaft继承并加强了Raft的安全规则。每一个控制器节点都会本地持久化重要的状态,如当前任期号(currentTerm)和投票记录(votedFor),以防止不合格的节点当选领导,保证领导者的唯一性。此外,通过日志匹配和追加原则,确保所有节点的日志在每个索引位置保持一致,避免分裂脑现象和数据不一致。 KRaft同样针对网络分区和集群拓扑动态变化提供了优化方案。实现了预投票(Pre-Vote)机制,有效阻止了因孤立节点引发的不必要选举,减少系统的短暂不可用时间。同时,动态图式法(Dynamic Quorum)允许集群在节点增减时平滑切换投票成员,保障安全的同时避免停机时间。
这些机制使Kafka在多节点扩展和维护时表现更加稳健和灵活。 在性能方面,KRaft协议通过支持并行文件系统同步和网络通信的设计,极大提升了日志写入及复制吞吐。同时引入批处理和流水线技术,优化了AppendEntries请求的处理效率,降低了领导选举延迟,提升了整体系统的响应速度和可用性。此外,控制器单线程事件循环模型也减少了并发竞争带来的复杂性和开销。 KRaft协议的出现,彻底改变了Kafka的运维模型。用户无须再独立部署和管理ZooKeeper集群,Kafka成为一个完全自包含的分布式系统。
这个转变不仅降低了运行成本,还减少了运维复杂度,极大提升了启动和扩展的便捷性。尤其是在云原生和容器化环境中,KRaft为Kafka的弹性扩展和自动化运维奠定了坚实基础。 从实际应用角度看,KRaft协议适用于各种规模的Kafka集群。单节点组合模式允许控制器和Broker共存,非常适合开发测试及小规模生产环境。大规模环境则推荐分开部署控制器和Broker,以充分利用资源并提升可靠性。Kafka社区持续投入优化和扩展,期望未来KRaft协议在功能完整性、性能和稳定性上更进一步。
综上所述,Apache Kafka的KRaft协议不仅是一次技术上的迭代,更是Kafka朝向现代分布式系统目标迈出的关键一步。通过取代ZooKeeper,整合Raft协议,Kafka获得了更强的元数据一致性保障、简化的系统架构和卓越的扩展能力。对于开发者与运维人员而言,理解KRaft的架构设计与实现细节,有助于更好地构建高可用、高性能的流处理平台,同时为未来的Kafka生态提供更多创新空间和可能性。随着大数据和实时计算需求的不断增长,KRaft无疑将成为Kafka保持领先地位的重要基石。 。