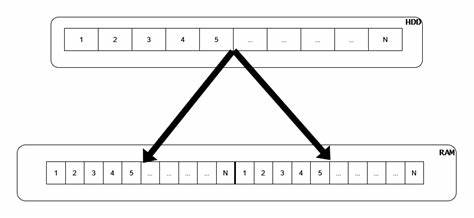
高性能进程间通信(IPC)是现代计算机系统中不可或缺的组成部分,尤其在多核处理器和分布式系统日益普及的背景下,实现高效、低延迟的数据交换机制成为开发者关注的重点。传统的共享内存通信方案虽然速度快,但在处理可变长度消息时往往面临内存碎片和复制开销等难题。针对这一挑战,双重映射连续共享内存无锁队列的设计方案应运而生,提供了一种创新且高效的解决思路。 双重映射连续共享内存无锁队列核心思想在于通过内存映射技术创建一块连续且环绕的地址空间,使得环形缓冲区的物理内存区域被映射到了虚拟地址空间的相邻两段,从而实现逻辑上无缝的环绕访问。这样的设计避免了传统环形队列在尾部与头部存在断裂问题,也有效解决了变量消息跨界存放需要额外复制的瓶颈。 具体实现中,开发者首先利用操作系统的匿名内存映射申请两倍大小的虚拟连续空间,然后将同一个队列文件映射到这两块相邻区域。
此举保证了对队列缓冲区的读取或写入过程中,应用层能够直接通过一个连续的内存块访问数据,避免了数据复制带来的性能损耗。为强化封装和方便资源管理,采用了一种资源获取即初始化(RAII)模式的映射管理类,确保映射的正确创建与销毁,避免内存泄漏风险。 竞争条件是多线程、多进程共享数据结构中亟需解决的问题。该队列通过精心设计的控制块实现读写指针的无锁管理。控制块保存了版本号、读写偏移量等重要信息,且通过C++17提供的std::hardware_destructive_interference_size特性,将读写指针分布在不同的缓存行中,有效避免了伪共享带来的性能下降。这种缓存行对齐技术在无锁数据结构设计中已被广泛认可,显著提升了并发访问的效率。
队列的操作接口设计简洁明了。写端通过get_buffer请求一段可用缓冲区直接写入消息内容,完成后调用push通知队列数据已写入。读端相应地调用get_buffer读取指定字节数内容,不复制数据直接访问,并在处理完毕后调用pop更新读取指针。整个过程不存在锁机制,依赖原子操作确保数据一致性与内存可见性,极大地提升了传输的吞吐量和响应速度。 消息体设计方面,示例中的消息结构体采用了#pragma pack(push, 1)指令严格控制内存布局,消除内存对齐导致的填充字节,保障消息在读取时能通过reinterpret_cast安全、直接地从缓冲区载入。这种技巧虽有一定的未定义行为风险,但在性能敏感型应用中被广泛采用,且未来的标准演进可能会进一步规范相关行为。
性能测试显示,双重映射队列在发送百万条消息时展现出极低的延迟,数据收发往返时间多集中在微秒量级甚至更低,利用现代CPU的高精度时间戳计数器(TSC)进行测量,结果证明此设计极大降低了内存复制和锁竞争开销。latency分布图反映出受各种缓存未命中的影响,但总体表现优异,适合高频、低延迟的IPC场景。 为进一步提升性能,开发者建议结合系统性能分析工具(如perf stat)观察缓存失效、分支预测命中率等底层指标,持续优化热路径代码,剖析汇编输出确保编译器已充分发挥指令级并行及流水线优势。此外,将该队列代码集成到真实大规模应用中进行测试,有助于发掘可能的瓶颈及改进空间。 与其他常用IPC方案相比,如boost::interprocess提供的共享内存队列,双重映射连续共享内存无锁队列在少数高性能需求场景中展现了独特优势。它适合变长消息传递且对延迟极度敏感的应用,避免了传统环形队列因消息断裂带来的数据复制或分離操作,确保了极致的零拷贝性能。
该方案体现了高级内存管理和并发控制手法的深度融合,既利用了操作系统底层的虚拟内存机制,也结合了C++现代特性和体系结构细节优化,是现代底层系统设计的典范。开发者可借鉴此思路针对特殊应用场景自主实现无锁、高效的IPC机制。 总结来说,双重映射连续共享内存无锁队列突破传统环形缓冲区处理可变长度消息的瓶颈,采用内存双重映射制造虚拟连续空间,实现零拷贝的高速消息通信。结合准确的缓存line隔离、无锁原子操作和高效的接口设计,展现出极佳的性能表现和优越的扩展能力。未来该技术有望在高频交易、实时数据流处理和高性能计算等领域发挥更大作用,激发社区不断创新和完善无锁数据结构设计方法。