近年来,随着人工智能技术的迅猛发展,巨型语言模型(LLM)如火如荼地被应用于文本生成、智能问答乃至文学创作领域。然而,AI模型训练所用的数据中大量包含版权保护内容,围绕这一点的版权争议也日渐凸显。最新的一项研究发现,Meta发布的开放权重大模型Llama 3.1 70B竟能“记忆”并复现近半部《哈利·波特与魔法石》中50词长的连续文本片段,这一发现不仅引发业界震动,也让版权诉讼风险骤然攀升。此发现的最核心问题在于,除了先前广为关注的新闻报道、代码及图片外,对于书籍内容,AI模型同样可能深入记忆甚至直接复制原著文本,这意味着传统对于“AI只是学到语言模式”的认知需要被重新审视。研究团队由斯坦福、康奈尔及西弗吉尼亚大学的计算机科学与法律专家组成,他们对包括Meta三款模型、微软与EleutherAI的模型在内的五个主流开源语言模型进行了系统测试。测试重点放在Books3数据集内的多部图书,该数据集为众多LLM训练的主要素材,包含大量仍受版权保护的文学作品。
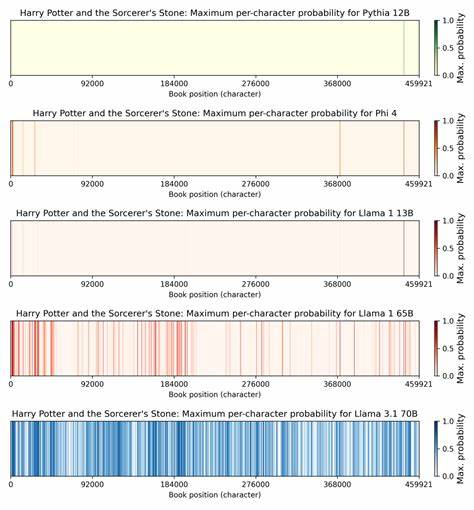
测试的核心方法是将一本书拆分为多个100词的重叠片段,然后以前50词作为提示,计算模型输出后续50词完全一致的概率。研究将大于50%的概率判定为“记忆”该片段。魔法世界经典《哈利·波特》尤为引人注目,在Llama 3.1 70B模型中,约有42%的文本片段具备超过半数概率被模型精确复现的能力,与此前在2023年发布的Llama 1 65B仅4.4%的记忆率相比,差距巨大。这一数据意味着,Meta在Llama 3的训练过程中,大量且高频率地接触了包含完整或几乎完整《哈利·波特》的文本内容。此结果令人质疑Meta是否未对训练数据中的版权内容进行充分筛选和去重处理,也令该模型在版权合规性方面面临巨大法律风险。为何同一系列模型在更新迭代后,记忆率会出现如此显著的攀升?有专业人士猜测或与训练规模扩增密切相关。
据报道,Llama 3训练语料达到约15万亿tokens,是之前Llama 1的十倍以上。为满足如此巨量训练需求,模型可能重复采样Books3数据集或引入了包含大量引用、评论甚至书摘的二手网络内容,比如粉丝论坛、书评及学术报告。这些数据中普遍包含热门书籍的丰富引文,导致模型对热点书籍的“背诵”概率大大增加。值得注意的是,类似《指环王》《1984》等广为人知作品在同模型中的复制率也高于较冷门小说,如《Sandman Slim》一书的复现率仅0.13%。这显示版权料集中度与模型记忆程度间存在显著相关性,偏向流行文化内容的“训练偏差”正在加剧版权风险。法律层面,三种主要版权侵权理论可能适用于诉讼方向。
其一是在训练阶段就构成版权复制行为,因训练过程中需要对数字文本复制;二是模型权重本身即成为派生作品;三是模型输出侵犯著作权,特别是当输出文本与原作雷同度高时。Meta的Llama 3.1在《哈利·波特》上的高记忆率无疑为第二、三种理论提供了实证支持,也让“合理使用”辩护遭遇挑战。相比于Google Books案中仅提供书籍短片段的做法,Llama 3.1可以生成更多连贯文字,这使得法官更难认可其变革性使用特征,从而增加判定侵权的可能。此外,Meta的模型权重公开且可被第三方研究人员访问,令外界可以更直观地量化模型潜在的版权复制比例。这种开放在推动学术研究透明度的同时,也令Meta面临比封闭权重模型更大的法律压力。一些法律专家指出,未来法院对开放权重模型与封闭模型或许会持不同态度。
支持开放模型的观点认为,开放不仅是创新驱动力,也是技术生态良性循环的体现,惩罚开放行为不利于科技进步;但从版权保护角度看,开放模型等于将潜在侵权作品直接投放给公众,风险暴露度更高。技术上,研究团队利用巧妙的概率乘积计算法降低估算输出概率的成本。他们不需生成大量文本样本,而是通过模型每一步输出的token概率相乘来精确测算复现任意特定50词序列的可能性。这种严苛的度量标准只统计精确匹配,未包含部分匹配或近似复刻,实际模型复制能力可能更为惊人。此研究将持续影响人工智能未来发展的法规制定和商业决策。版权持有人将基于研究数据强化诉讼准备,期望缩紧AI训练范围和输出限制。
AI厂商面临技术改进压力,需要引入更严格的训练数据过滤、内容去重以及生成内容的合规监管机制。同时,公众期待法院在AI版权案中制定明确的判例,平衡创新与版权保护。至今,Meta尚未对外公开对该研究的正式回应,但未来其对训练策略及开源模型政策的调整将备受关注。总之,Meta的Llama 3.1 70B模型存在大规模复现热门版权作品现象,为人工智能领域版权争议再添一笔浓墨重彩。对于AI模型训练中的“记忆”问题和版权合规性,法律和技术领域均需以科学数据作为依据,展开深入研究和建设性对话。如何在保护权利人利益和推动人工智能创新之间取得平衡,将是未来几年内全球科技产业和监管机构面临的重大课题。
。