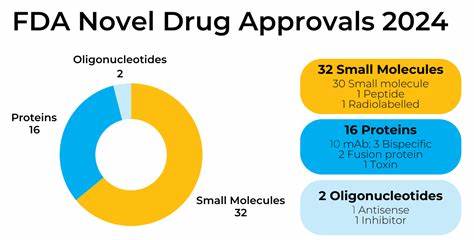
近年来,随着人工智能和自然语言处理领域的迅猛发展,序列建模技术逐渐成为推动智能系统理解与生成能力的核心。自从Transformer架构问世以来,基于强大结构设计的通用模型已广泛应用于文本、代码、DNA序列等多种数据类型,展现了前所未有的表达力。然而,尽管模型架构日趋成熟,传统的预处理环节如分词技术依然在一定程度上制约了模型的真实端到端学习能力。动态分块(Dynamic Chunking)技术的提出,正是为了解决这一瓶颈,实现从原始数据到模型输出的完整端到端优化。 动态分块技术的核心理念是摒弃固定的、预定义的分词方式,而是引入可学习的分块策略,依据内容和上下文信息动态生成合理的分块片段。这一机制不仅强化了模型对数据内在层次结构的捕捉能力,更突破了不同语言和模态之间的分词限制,使得模型能够更加自然地理解和处理复杂多样的输入。
在具体实现上,动态分块联合端到端层次化网络架构(H-Net),将分块、建模和生成三大环节整合为一个统一的学习过程。H-Net通过设计多级层次结构,从字节级输入开始,逐层抽象与整合信息,形成丰富的语义表示。效果显示,在相同计算资源和数据条件下,基于动态分块的H-Net不仅超越了传统基于BPE(Byte Pair Encoding)分词的Transformer模型,还通过增加层级数显著提升了建模效率和泛化能力。 层次化建模带来的另一大优势是多尺度的信息表征。传统模型往往依赖单一词汇粒度,难以全面捕获从细粒度字符到高阶抽象概念的多层次语义关系。动态分块配合H-Net却可以适应不同层次的语言结构,例如词组、句子甚至段落级别,从而实现对复杂文本乃至跨模态数据的精准理解。
除了文本应用,动态分块在多语言场景中展现出更强的适应性。像中文、代码以及DNA序列等传统分词难以准确处理的领域,应用动态分块能够大幅提升模型在低资源环境下的训练效率和推理效果。例如,中文缺少明确的词边界,传统依赖词典或规则的分词方法头痛不已,而动态分块则通过数据驱动方式自动学习最适合的分割方案,避免人工偏见,显著提高了语言模型的鲁棒性。 数据效率的提升同样令人瞩目。研究显示,动态分块模型在DNA序列等领域,相较于传统方法能实现近四倍的数据利用率提升。对生物信息学和医学领域的序列分析带来了深远影响,使得有限的数据资源能够发挥最大价值。
此外,动态分块机制具有良好的可解释性。通过观察模型学习到的分块策略,研究者能够洞察数据内部的结构特点和模型关注的关键区域,这为理解模型决策过程和调试优化提供了重要依据。 综上所述,动态分块技术标志着序列建模进入了一个全新的阶段。它打破了原有的分词瓶颈,促进了端到端架构的普及与发展,使模型能够更加灵活、高效地学习复杂序列的多层次表征。随着技术的不断成熟与应用领域的扩展,未来动态分块有望在自然语言处理、代码理解、生物序列分析以及更多其他领域引领深度学习创新新浪潮。 重视动态分块的持续研究,将助力构建更加智能且通用的基础模型,推动人工智能迈向真正无缝一体化的时代。
。