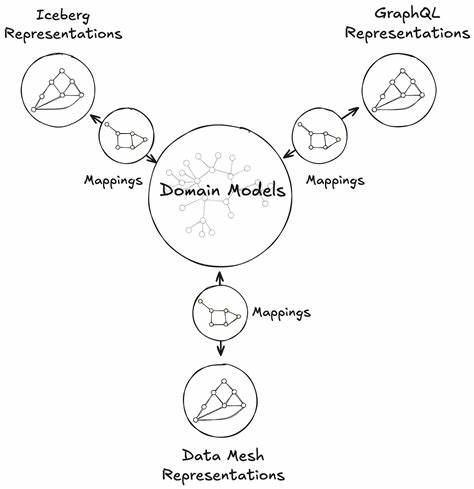
随着数据驱动时代的不断发展,企业在面对海量数据时,如何高效、统一地构建和应用数据模型,成为决定业务竞争力的关键因素。Netflix,作为全球领先的流媒体平台,开创性地提出并实践了统一数据架构(Unified Data Architecture, UDA)理念,打破了传统数据孤岛,推动了模型从构建到应用的全流程优化,实现了“模型一次构建,多处代表(Represent Everywhere)”的创新范式。业务和技术的深度融合也使得Netflix在内容推荐、用户画像及运营分析等方面保持了卓越的竞争优势。Netflix的UDA核心理念在于构建一个统一且高效的模型生态系统,不再需要针对不同业务场景重复开发和训练相似的数据模型。通过集中管理和共享基础的数据科学资源,Netflix大幅减少了模型开发的重复劳动和维护成本,同时保证了数据分析和机器学习结果的一致性。UDA架构不仅支持从数以百计的数据源汇聚信息,还能够通过可扩展的平台,将数据转化成经优化的机器学习模型,供多种应用场景立即调用。
技术实现方面,Netflix构建了一套覆盖数据采集、存储、处理与建模的端到端框架。首先,数据从多样化的源头如用户行为日志、设备信息和内容元数据中实时采集,并进入高度整合的数据湖系统。数据湖通过大规模分布式计算引擎,保障数据的快速处理和高效存储。基于统一的数据标准和丰富的数据治理策略,确保数据质量与安全性,为模型训练提供坚实基础。在模型层面,Netflix采用先进的机器学习算法和深度学习框架,结合特征工程、自动超参数调优等技术,产出高效、准确、可复用的模型。更为重要的是,这些模型被设计为可在不同产品线和业务单元中复用,真正实现了“模型一次编写,代表无处不在”。
UDA促进了Netflix内部的协作文化,数据科学家、工程师和业务团队之间的壁垒被显著打破。统一的模型库和API接口使得各团队能够便捷地调用和调整模型,快速响应市场变化与用户需求,缩短了产品迭代周期。这一流程改进也降低了模型从研发到生产应用的门槛,推动了创新的持续发生。在内容推荐方面,UDA发挥了极致的效率。Netflix利用统一模型对用户观看习惯、内容特征、互动行为进行多维度分析,从而精准推送个性化推荐,不断提升用户满意度和平台粘性。此外,UDA还在用户画像构建、流量分析、广告投放优化等多个业务场景中发挥关键作用,实现了数据价值的最大化。
机器学习模型在UDA框架中的共享能力,也为Netflix全球扩展提供了强大支撑。通过统一架构,模型可以快速适配不同地区的文化偏好和内容偏好,支持多语言和跨地区的产品本地化需求。这样的灵活性确保了Netflix能够在多元化市场中保持领先地位。安全性和数据隐私在UDA设计过程中同样受到高度重视。Netflix结合最新的加密技术和访问控制策略,确保数据模型和用户信息的安全无虞。全面的日志记录和监控体系,也使得数据流转环节透明可控,满足全球范围内日益严格的数据合规要求。
未来,Netflix计划继续深化UDA的智能化水平,借助自动化机器学习(AutoML)、联邦学习和边缘计算等前沿技术,进一步增强模型的自适应能力和实时响应性能。UDA将成为推动Netflix数字化转型的重要引擎,支持更加丰富多样的业务创新。总的来说,Netflix的统一数据架构引领了企业级数据治理和机器学习应用的新趋势。通过模型一次构建、多处代表的策略,不仅提升了技术效率,更赋能业务快速变革和创新,实现了数据向价值的高效转化。Netflix的UDA经验为其他行业数据架构设计提供了宝贵借鉴,展现了未来数据驱动企业的广阔前景。