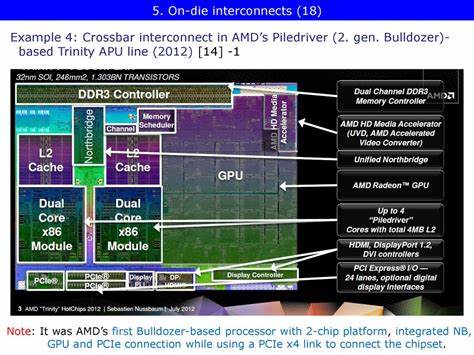
近年来,随着集成处理器(APU)在计算领域的重要性不断提升,AMD通过其创新的芯片互连设计,实现了CPU与GPU的紧密结合,为图形计算和通用计算带来更高的效能和更低的延迟。在Zen架构推出之前,AMD在2012年推出的Trinity APU凭借其独特的北桥设计,成为其集成GPU发展道路上的重要里程碑。本文将深入探讨Trinity北桥互连架构的设计理念、实现机制以及实际表现,帮助读者全面理解AMD早期APU架构设计的优势与不足。AMD Trinity APU是基于两个双线程Piledriver模块和一个6 SIMD Terascale 3集成GPU构建的处理器,以A8-5600K为代表型号,在当时搭载了四个Terascale 3 SIMDs,CPU频率从最高4.2 GHz降至约3.9 GHz,配合主板如MSI FM2-A75MA-E35及16 GB DDR3-1866内存组成完整平台。Trinity的北桥架构源自较早Athlon 64时代,将传统芯片组北桥的功能迁移到了CPU内部。北桥核心部分独立在一个频率为1.8 GHz的电压和频率域,使其在处理CPU核心与内存请求时能够实现较低的延迟。
北桥的总体结构采用两级交叉开关设计,第一层是系统请求接口(SRI),CPU核心通过SRI提交请求,该接口负责将请求分配至不同队列,其中大多数内存请求流向系统请求队列(SRQ);此外,SRI还处理外部探测请求,并将其分发至CPU。第二层交叉开关(俗称XBAR)连接SRI的各种队列,负责将请求路由至IO或内存子系统。该XBAR不仅支持IO间通信,虽然此类通信在消费级系统中较少出现。Trinity的XBAR调度器(XCS)拥有40个条目,相较于同时代桌面和服务器用Piledriver处理器的64条目较小。AMD默认将XCS条目分配为22条给SRI,10条给内存控制器(MCT),8条给上行信道,但BIOS可根据需求调整此配置。XBAR负责向内存控制器发送请求,MCT根据请求类型和等待时间优先处理内存请求,并内置了基于步进访问模式的预取机制。
MCT作为缓存一致性维护者,可以发送探测信息予XBAR,是物理地址向“归一化”地址(仅覆盖由DRAM支持的内存空间)转换的关键环节。Trinity区别于CPU只有版本的显著特征在于其内建GPU专用的图形内存控制器(GMC)。GMC负责调度和仲裁不同请求,以最大化DRAM带宽的利用率,相当于在GPU侧实现了类似CPU MCT的功能。GMC通过一条名为“Radeon Memory Bus”(内部代号为“Garlic”)连接到DRAM控制器,这条路径绕开了MCT,从而绕过了北桥的缓存一致性机制。同时GPU通过第二条控制链路(曾称“Fusion Control Link”或“Onion”)与XBAR相连接,这条链路类似于其他IO设备的控制通道。两个链路“Garlic”和“Onion”共同构成Trinity中CPU与GPU之间基础但却分明的互连系统。
Garlic链路设计的核心亮点在于其可让GPU实现DRAM带宽的最大化利用。绕开MCT意味着此路径不参与缓存一致性机制,避免了CPU缓存被GPU内存请求频繁探测带来的开销和功耗。这种侧重数据不共享的设计避免了无效的缓存探测流量。然而绕开MCT也意味着划分了CPU和GPU对内存的访问路径,使得两者不能在高速缓存层面实现无缝的数据共享。为防止CPU与GPU相互饥饿,MCT和GMC会在DRAM控制器队列中限制未决请求数,DRAM控制队列可以轮流或优先接受来自一侧的请求。整个机制保证了CPU端较高的访问响应时间。
同时,Trinity BIOS文档显示Garlic链路可能拥有多达16条的读指针队列,为数据传输提供了必要的缓存和平滑能力。实际测试表明,即使GPU在DRAM上高强度读写超过24 GB/s,对CPU端响应延迟影响有限,保持在120纳秒内;在纯CPU负载饱和时延反而更高,这表明DRAM访问控制机制对CPU端性能有更直接的影响。相比之下,Onion链路承担了GPU访问CPU可缓存主机内存的任务,支持软件通过OpenCL编程时将数据缓存在缓存中,实现GPU零拷贝访问。但是该链路不支持高带宽传输,峰值带宽不足10 GB/s,同时缺乏探测过滤器,导致探测响应次数飙升,造成大量错误探测流量。此现象反映出北桥设计未能有效限制探测流量,使其成为性能瓶颈。值得注意的是,当GPU内存空间不足时,会使用Onion链路访问较大缓冲区,代价是额外约320纳秒的访问延迟。
整体而言,Trinity的Onion链路虽实现了缓存一致性保证的功能,但性能损耗明显。CPU访问GPU内存方面,Trinity支持通过CL_MEM_USE_PERSISTENT_MEM_AMD等标志,将GPU内存映射到CPU地址空间,但出于一致性方面考虑,CPU端映射区域被设置为不可缓存或写合并模式。这一限制避免了缓存更新带来的数据不一致风险,但牺牲了缓存带来的访问性能优势。数据访问中,CPU访问GPU内存表现出较高的访问延迟(约93纳秒),同时仅支持单条未决读请求,无法充分利用内存级并行性。此外,CPU无法合并同一缓存线的多次读请求,影响效率。相比之下,现代基于Zen架构的Infinity Fabric实现了CPU和GPU间统一、缓存一致且高效的内存访问,GPU访问内存时可享受缓存保持、低延迟访问。
总体来看,Trinity的北桥设计虽存在架构局限,但也体现出当时AMD为兼顾CPU与iGPU性能做出的技术权衡。在实际应用中,Trinity以其较强的集成显卡性能为主打卖点,适合预算有限的游戏体验。通过图形基准如Unigine Valley和Final Fantasy 14: Heavensward实测,iGPU带来了大量DRAM带宽需求,带宽最高可达22.7 GB/s。相比CPU侧3-5 GB/s的带宽,GPU几乎承担了大部分内存数据传输压力。同时,MMO游戏如The Elder Scrolls Online在1080p低设定下表现尚可,CPU带宽需求偶尔攀升,与特定场景卡顿相关。图像处理软件如RawTherapee和Darktable则表现出不同的带宽分布和IO流量,反映了CPU/GPU异构协作的实际负载。
尽管Trinity时代的北桥互连设计与现代统一互连体系如Infinity Fabric相比缺乏优雅和高效,但其通过分离带宽密集型GPU访问路径及CPU缓存一致性路径,实现了当时条件下的合理折中,并为AMD后续APU架构的发展奠定基础。纵观当时,Intel的Sandy Bridge/iGPU基于环形互连实现CPU核心与GPU共享L3缓存,结构较为紧凑,但其集成GPU性能不及AMD Trinity。几年后AMD推出的Zen架构则通过Infinity Fabric统一了CPU与GPU内存访问和缓存一致性,显著提升整体性能协同。Trinity代表了AMD首次真正尝试将强大GPU与CPU紧密组装于片上系统,推动了集成计算向更高性能迈进。虽然设计上仍存在诸多约束和性能损失,但其创新意义不容忽视,成为AMD触发APU强劲发展浪潮的重要起点。随着技术不断进步,未来CPU与GPU架构更加趋于融合与统一,零拷贝、统一缓存和高带宽访问将成为标配。
回顾Trinity北桥的研发过程,启示我们在微架构设计中权衡性能、功耗及一致性机制的重要性,也彰显出AMD在面对技术挑战时的创新精神和系统思维。这样的演进史不仅为玩家带来更好性能体验,也推动了整个计算生态的加速发展。