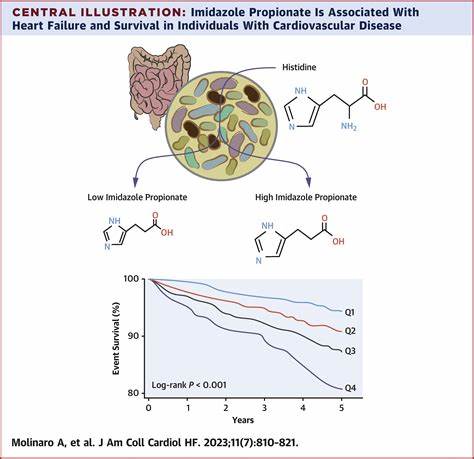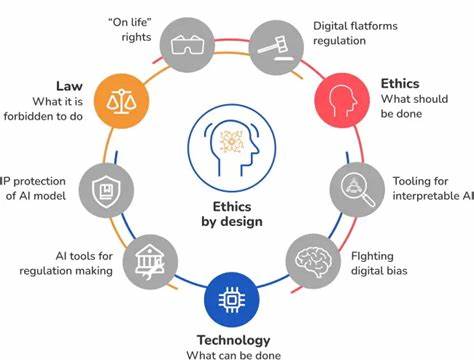
人工智能技术的迅猛发展正在深刻改变信息获取与知识传播的方式。尤其是生成式人工智能,如大型语言模型(Large Language Models,简称LLM),极大促进了人们获取信息的便捷性和效率。它们承诺打破传统机构和资质对知识的垄断,让知识更加自由流动,只要有人会提问,知识就能触手可及。然而,知识的可获得性并不意味着真正在数字社会中实现了知识解放。这其中的关键在于,我们必须关注不仅仅是知识的产生,更重要的是知识的治理和基础设施的构建。知识无力的本质,正源于知识之上的权力结构和技术设计的伦理局限。
彻底理解这一点,有助于我们更清晰地审视人工智能的未来走向及其社会影响。 大型语言模型虽然展现出泛化知识的强大能力,这类工具如OpenAI的ChatGPT和Anthropic的Claude在提供知识服务方面突破了传统边界,但它们运行的背后依托的是私有基础设施、封闭的训练数据以及带有提取本质的商业模式。这种模式下,知识虽易触达,却依然被少数私营企业掌握和控制,造成知识分配的不平衡和社会权力的集中。所谓的“中立工具”其实掩盖了隐藏在技术设计与数据治理中的权力偏向,甚至加剧了社会不平等。比如一些标榜“开源”的模型,它们虽然公开了部分模型权重,但核心训练代码依旧封闭,加之运算资源需求高昂,使得小型团队和个人用户难以真实利用。这种“开放”的假象反而强化了技术壁垒,限制了公众真正参与其中的可能性。
技术基础设施从来不是中性的。它不仅承载着数据和计算的物理基础,更内嵌着价值判断和政治选择。哪些数据被纳入训练集,哪些语音成为主流,哪些真相被授予权威,实际上都是技术设计中无法回避的决策问题。通过算法和模型对知识的筛选、强化、再现,人工智能系统往往边缘化非主流的认识论,强化现有偏见,控制话语权,形成新的“信息封闭区”。这种现象提醒我们,人工智能不是命中注定的进步,而是设计的结果。设计本身就是政治的过程,决定了谁能从中获益,谁被忽视,又是谁掌握权力。
更为严重的是,许多大型语言模型依赖从公共网络和私人平台大规模爬取的数据,无数用户在与AI交互时生成的行为数据和上下文信息,被平台默默收集和货币化。用户数据作为无形资产成为企业竞争优势的重要资本,这种隐形剥削加剧了数据权利的私有化。换句话说,公众话语和个人输入逐渐变成了私营企业的原材料,造成公共空间的进一步封闭。缺乏有效的透明度和用户授权机制,导致监控常态化风险提升,公共的数字基础设施难以建立在真正的信任和共识之上。 在数字世界里,知识的脆弱性和其赖以存在的基础设施密切相关。生成式内容的泛滥,使得对知识来源、真实性及其传播路径的辨识能力尤为重要。
建立具有伦理性、开放性和参与性的数字基础设施,成为保障知识可信度和治理的必要条件。诸如万维网联盟(W3C)和去中心化身份基金会(DIF)等组织提出了数据主权和去中心化控制的技术规范和模式,尝试将身份认证、凭证管理和数据权利从平台手中回归到个人与社区之中。这种以人为中心的系统设计设想了一个人类代理权得以彰显的AI生态,而非单纯的技术治理。 必须强调的是,人工智能的普及与技术更新,并不意味着我们可以忽视协议和规章——它们仍然是实现有效治理的骨架。没有明确的价值导向和公开参与的制度安排,技术发展只会重蹈中心化、缺乏透明和弱化个体权利的覆辙。正如众多学者和社会运动者所指出,监管固然重要,但更应注重治理的形式——共享规则、公开流程以及参与权的保障,才是真正的民主化。
缺乏参与性的AI基础设施无异于加速失控的系统,它未必造福大众,反而拓宽了控制的边界。 从技术发展的速度、规模及效率等传统指标来看,过去几十年我们见证了信息技术的爆发式增长。但当下的挑战已超越了单纯的性能竞争。我们亟需以信任、尊严和设计伦理为新的衡量标准,尊重人类本质的多样性和复杂性。未来的人工智能,不能简单地由技术自身决定其走向,而必须依据我们选择赋予它的社会价值和责任。唯有如此,我们才能实现真正解放的知识体系,不让智能规模成为权力滥用的工具,而将其塑造成包容与共治的平台。
最终,人工智能的力量如何被使用,取决于我们围绕其构建的协议、政策与社区建设。那些反映公共利益、体现社会价值的体系,将决定知识是否成为全社会共享的公共财富。遗憾的是,当前的大部分人工智能依然处于封闭且不可追溯的权力结构中,知识虽然近在咫尺,却无力撼动既有的控制格局。面对这一现实,我们需要持续呼吁和推动技术民主化、治理透明化以及设计伦理的完善,让人工智能成为真正的公共基础设施,而非权力再生产的工具。建设这一未来,是拥抱技术进步与守护社会正义的共同使命。