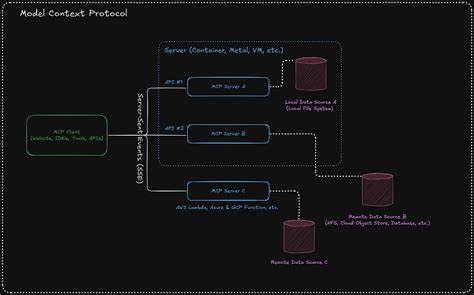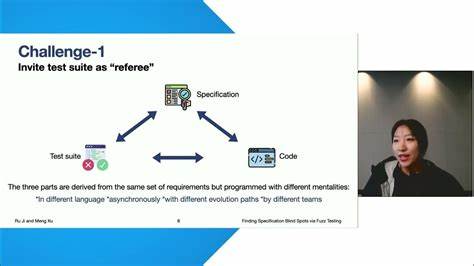
模糊测试(Fuzz Testing)作为一种自动化测试手段,凭借其能在海量状态空间中高效寻找程序漏洞的能力,已成为现代软件质量保证的重要利器。然而,模糊测试并非万能,它也存在覆盖盲区,尤其在复杂系统的特定组件中,这些盲点往往掩盖着严重缺陷。本文以著名分布式系统一致性测试工具Jepsen与高性能数据库TigerBeetle的合作为背景,深入分析模糊测试的盲点。并结合实际案例,揭示模糊测试的固有限制和针对性优化的必要性。 在软件系统中,组件功能与属性的复杂度差异明显,某些确定性强的模块可以通过传统测试工具轻松构造测试用例并验证结果,这些模块往往被模糊测试工具广泛覆盖。相反,涉及输入输出操作、状态副作用及多层次异步交互的组件测试难度较大,测试覆盖率也相对较低。
因此,系统的缺陷分布呈现出“明亮中心”与“暗角落”的明显对比。 TigerBeetle作为高性能分布式数据库,内部包含多个子系统,其中查询引擎是系统关键且功能丰富的组件。此组件被四种不同类型的模糊测试器覆盖,使得系统团队对其稳健性极为信任。然而,Jepsen在去年对TigerBeetle展开一致性和健壮性测试时,意外发现了查询引擎中的一个正确性缺陷,这一发现引发了深刻思考:既然该组件已被多重模糊测试覆盖,为什么依然未被原有模糊测试工具捕获? Jepsen的测试起因为在进行账户转账操作后,发起查询以获取相关转账记录,理应返回准确且完整的结果集。然而在一次测试中,创建的转账记录被群集系统确认无误,后续查询却未返回该记录。这种结果与Jepsen独立构建的参考模型结果明显不符,暴露出数据库查询结果中的异常。
进一步细致的分析表明,该异常仅在查询条件涉及多个字段交叉过滤时出现,例如同时使用用户数据标识和借方账户ID两个字段进行查询时,结果会出现缺失。 针对这一异常,团队对TigerBeetle现有的各模糊测试器进行审查。TigerBeetle约有二十个模糊测试用例,其中四个专门测试查询引擎,分别涵盖单树和森林级别的存储层结构,设计目的均为覆盖查询的多样场景。由于缺陷涉及跨多个树的字段交叉查询,孤立树的测试无法触发该问题。森林级的模糊测试虽然能访问多树数据,但查询操作始终限定于单树,未触及多树交叉检索逻辑。务实的查询模糊测试和VOPR(TigerBeetle的确定性模拟器)虽然能在一定程度上产生多树交叉查询,但二者的测试用例生成逻辑高度相似,模糊测试的输入空间结构过于局限,未能触发关键缺陷。
调查发现,模糊测试工作的核心问题在于其初始测试用例的结构设计。VOPR在初始化时预构建了一系列查询交叉模型,每个查询目标字段采用严格间隔的设定,如用户数据字段的数值依序叠加固定步长,确保每组查询条件对应唯一且不重叠的数据范围。每笔创建的转账数据都严格归属于事先定义好的某个查询交叉条件集。如此设计的初衷在于简化后续查询结果的统计和验证,避免构建完整的查询引擎模拟模型。然而,这种测试输入的高度结构化反而埋下了隐患,使测试样本在索引中呈现连续且不重叠的分布,导致不同索引间查询条件高度同步,从而不需要跨索引探测跳跃,错过了触发交叉迭代器“探针”机制的机会。 正是这种设计上的无意“投影”使得模糊测试无法覆盖到涉及多索引异步迭代的复杂场景,从而导致漏检。
针对这一缺陷,团队尝试放宽测试输入限制,采用完全随机化的调用和查询策略,引入了精细的数据库模型用于输出校验,这种方法摈弃了此前预先构造的结构,直接模拟多字段交叉查询及其复杂交互。结果表明新的模糊测试能轻松复现之前未被捕捉的查询结果缺失问题。 关于具体的缺陷来源,TigerBeetle在执行多索引交叉查询时,分别基于用户数据字段和账户ID构建异步迭代器,这些迭代器遍历基于时戳的排序结构。实际交叉操作采用了先进的交叉归并算法——Zig-Zag Merge Join,该算法通过迭代器间的“跳跃探针”优化交集计算,能够有效避免完全扫描所有数据,极大提升查询效率。然而,对迭代器范围的调整引入了边界条件的复杂性。当某个迭代器被探针跳跃并且其当前缓冲层耗尽时,系统尝试加载下一数据表,但原有判断逻辑未能准确区分是因为迭代范围自然结束还是探针导致范围收缩,错误地提前终止了迭代过程。
这种条件判断的细微失误导致部分匹配记录被提前截断,最终查询结果出现遗漏。 修复方案聚焦于对迭代范围边界条件的判别逻辑进行了改进,使系统能够正确识别因探针机制导致的范围缩小情形,避免盲目停止迭代。同时保持对真正遍历完成情形的准确判断,保障查询结果的完整性和正确性。该补丁有效解决了模糊测试发现的正确性问题。 从整体视角来看,Jepsen与模糊测试的协同验证过程指出了模糊测试工具在输入空间设计上的常见风险,尤其是在针对高维、多索引、异步行为强的系统时,过度结构化的测试用例可能成为盲点的温床。模糊测试虽然强大,但其不均匀采样策略由人为或者自动化设计的输入分布偏移决定,某些“关键状态”即使重要,却难以由传统模糊策略生成。
模糊测试的成功与否,取决于测试输入对系统状态空间的覆盖深度和广度。 因此,建议在系统测试设计中,结合简单的随机测试策略与针对性的、有模型指导的复杂测试策略,从而弥补单一策略的偏差和盲点。特别是在复杂数据库系统或分布式系统中,构建与系统行为密切相关的参考模型,用其验证测试输出,可以有效提升测试发现缺陷的能力。 此外,系统工程师应持续关注测试工具的设计限制,审视模糊测试框架中预设的假设和输入约束,避免对测试空间施加无意障碍。仅依赖某一类测试工具可能导致错失潜在缺陷。多样化和迭代优化测试策略,才能达到理想的测试覆盖效果,从而保障系统的鲁棒性和正确性。
总结而言,模糊测试是寻找复杂软件缺陷的利器,但并非全能。TigerBeetle与Jepsen的合作案例生动展示了模糊测试盲点的形成机制、发现过程及有效的改进路径。开发团队应借鉴此案例经验,对测试体系进行持续完善,避免盲点造成的安全隐患或功能错误。未来,结合多维度测试方法和完善模型验证,将是提升复杂系统质量的关键方向。