在人工智能技术快速发展的当下,基于大型语言模型的代理工具与智能工作流正在逐步重塑各行各业的数字化模式。大型语言模型,如GPT系列,凭借其强大的自然语言理解与生成能力,被广泛应用于搜索引擎、自动化客服、数据分析等场景。然而,这些模型在实际应用过程中,尤其在多步骤、多工具组合的复杂工作流中,面临着性能瓶颈和成本挑战。如何有效优化工具选择,提升工作流的整体效率,成为研究热点。可微分编程在此背景下提供了革新性的解决方案,通过将工具选择机制设计为可训练的神经网络控制器,实现了传统基于语言模型提示的串行决策策略的升级。传统的LLM工具选择方法通常依赖多次调用语言模型本身来决定调用哪一个外部工具。
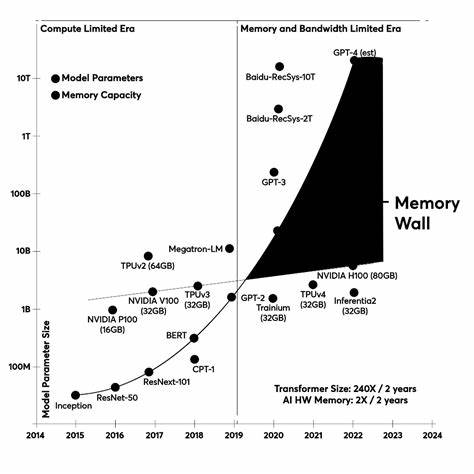
这种做法虽然直观易用,便于快速搭建样例,但在实际运行中却存在显著缺陷。每一次调用都会产生延迟和计算资源消耗,更重要的是,随着工作流步骤的增加,所需维持的上下文信息呈指数增长。这种上下文膨胀不仅加重了计算负担,还导致模型效能降低、响应时间延长,同时增加了整体成本。上下文膨胀具体表现为重复传递历史输入、先前决策和中间计算结果,造成“令牌税”(token tax)现象;此外,长期上下文超过模型输入限制,出现截断风险;注意力机制被稀释,使得关键内容难以突出;甚至存在逻辑泄漏,前置规划影响最终回答的准确性。面对上述问题,学界和工业界开始探索将工具选择过程剥离出语言模型,采用更为高效的可微分路由器(differentiable router)来替代传统的提示工程。该路由器作为轻量级神经网络模块,直接接收任务输入信息,输出各工具调用的概率分布,从而进行动态决策。
这种设计带来诸多优势。首先,可微分路由器可以通过监督学习或强化学习方式基于历史调用日志进行训练,不断优化工具选择策略,应对任务多样化。其次,路由过程不涉及额外语言模型推断,显著节省了API调用次数,降低延迟及成本。再次,路由器的决策过程透明可追踪,便于调试和性能监测。最后,可微分路由器与PyTorch等深度学习框架完全集成,可灵活与其他神经模块、控制逻辑组合,共同构建完整智能工作流。以PyTorch实现的简易四层神经网络为例,输入经过分词编码后传入网络,输出是针对各可用工具的softmax概率分布。
整个网络的参数可通过梯度下降算法训练,反向传播使得工具选择依据实际任务反馈不断迭代优化。数据可以从现有交互日志获取,也可以利用预训练大模型生成合成样本,降低训练成本。在实际部署中,区别于基于语言模型提示每次诱导计划和调用工具,差分路由控制器只需一次输入即可精确选定工具,最终向语言模型传入的仅为用户原始查询及所选工具结果,解决了上下文膨胀问题,实现了上下文长度的恒定。该架构将传统将工具选择和内容生成混合的复杂流程进行解耦,二者分别由轻量级神经路由模块和强大的语言模型承担,使得系统更加模块化、可维护且可扩展。此举不仅提升系统整体性能和稳定性,还根本降低了因多轮调用产生的经济负担,尤其是在长期运行和大规模部署场景中优势明显。战略层面来看,可微分编程辅助的工具选择标志着人工智能体系结构从“提示链”式流程向“程序化”式流程的转变。
简言之,前者过度依赖语言模型进行所有决策处理,效率低下且不易管理;后者通过神经模块实现可学习的控制流,实现声明式控制与生成推理的分离。这种分工清晰的模式,有助于构建具备更好解释性和调试性的高性能智能代理系统。为进一步验证该方法的性能,相关研究进行了PyTorch与数字信号处理库DSPy的集成实验,实现了差分路由控制器替代提示规划器的对比测试。结果显示,差分路由架构在推理速度和成本节省上表现突出,且具备良好的训练稳定性和收敛性能,适合应用于复杂多工具、多步骤的应用场景。实践中,如何获取标注或合成样本是关键挑战,另外路由器模型的规模和复杂度也直接影响整体系统的响应时长。值得进一步探索的是结合更丰富的上下文理解以及多模态信息输入,提升工具选择的智能度和泛化能力。
同时,结合强化学习反馈机制,实现路由策略的在线自适应,为高度动态和不确定的任务环境提供支持。总之,可微分编程在优化大型语言模型工具选择中展现出极大潜力,为未来智能工作流的自动化与智能化开辟了重要方向。随着技术成熟和规模应用扩展,预计基于差分路由的代理系统将成为智能服务设计的主流方案,显著推动人工智能赋能工程的进步。面向未来,持续深耕可微分编程理念与技术,打造更智能、更高效、更经济的语言模型工作流,是推动AI产业健康发展的必由之路。