随着人工智能技术的飞速发展,文本嵌入和重排技术在信息检索、自然语言理解等领域的重要性日益凸显。Qwen3 Embedding系列作为Qwen模型家族的新成员,凭借其独特的技术优势和广泛的应用前景,迅速成为业界关注的焦点。该系列以Qwen3基础模型为核心,融合了多种先进训练方法和优化策略,为文本嵌入与重排任务提供了全新的解决方案。 Qwen3 Embedding系列的最大优势之一是其卓越的多语言能力,支持100多种语言和多种编程语言。这使其在全球化应用和跨语言检索场景中表现尤为出色。多语言支持不仅提升了模型的适用范围,也为企业和开发者打造了跨文化沟通和智能检索的桥梁。
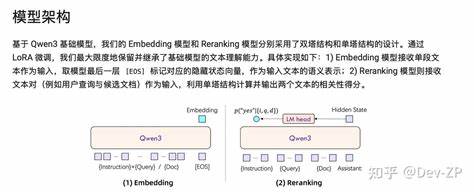
基于Qwen3强大的多语言文本理解能力,该系列在多个基准测试中实现了前所未有的高性能,尤其是在MTEB多语言排行榜上,8B规模的嵌入模型荣登第一,展现了其卓越的技术实力。 从模型规模和结构上看,Qwen3 Embedding系列涵盖了0.6B到8B不同参数规模,满足不同场景对效率与效果的平衡需求。无论是资源受限的轻量级应用,还是追求极致性能的复杂任务,都能够找到合适的模型版本进行部署和调优。此外,模型设计兼顾灵活性,支持自定义向量维度和用户指令,这意味着开发者可以根据具体任务、语言或场景调整模型输入和输出,从而进一步提升模型在实际应用中的表现。 技术层面,Qwen3 Embedding系列采用了双编码器(dual-encoder)和交叉编码器(cross-encoder)架构,通过LoRA微调策略最大限度地继承和增强基础模型的文本理解能力。嵌入模型主要处理单一文本段,提取其语义表示,重排模型则采用交叉编码方式输入文本对,计算相关性分数,适配复杂的文本匹配和排序需求。
此外,训练过程恰当结合了大规模弱监督数据的对比预训练、高质量标注数据的监督训练以及多模型融合策略,确保模型兼具良好的泛化能力和任务适应性。 尤其值得关注的是训练阶段中引入的多任务适应提示系统。借助Qwen3基础模型的文本生成能力,系统动态生成针对不同任务类型和语言的弱监督文本对,突破了以往依赖社区论坛或公开数据收集限度,为大规模数据构建提供了创新思路。这不仅提升了训练效率,更增强了模型在多样化应用中的表现力,为未来多任务、多语言模型训练树立了典范。 在实际应用中,Qwen3 Embedding系列的表现已在多个文本检索、代码检索等场景得到验证。无论是信息检索场景下的候选文档重排,还是自然语言理解领域的语义表示提取,其稳定且领先的得分证明了模型的强大实力。
特别是重排模型在MTEB-R、CMTEB-R等多个子集上的优异表现,体现了其在提升搜索相关性和用户体验方面的巨大潜力。 未来,Qwen团队计划继续优化基础模型,提升嵌入和重排模型的训练效率及部署性能,推动模型在更多应用场景中的深入扩展。同时,多模态表示系统的研发也在稳步推进,希望实现跨模态语义理解能力,进一步丰富模型的表达能力和应用范围。随着生态的不断完善,Qwen3 Embedding系列将成为多语言文本处理和智能检索领域的重要基石,助力开发者和企业实现更智能的内容理解与交互。 综合来看,Qwen3 Embedding系列不仅展示了先进的文本嵌入与重排技术,更体现了基于大规模基础模型的创新训练理念和应用转化能力。它为复杂多语言环境下的信息处理提供了强大支持,预示着文本理解技术向更智能、更高效方向迈进的新趋势。
未来,随着持续的技术迭代和生态建设,Qwen3 Embedding系列必将在智能搜索、跨语言沟通、代码检索等领域发挥越来越关键的作用,推动人工智能赋能社会的广泛深化。