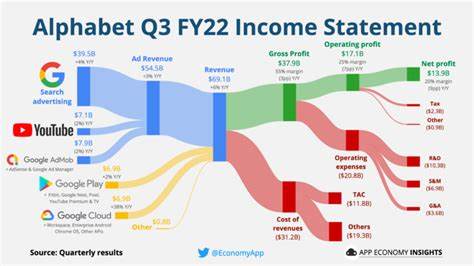
在现代前端开发领域,React凭借其声明式编程风格和组件化架构,成为构建动态用户界面的主流框架。无论是小型项目还是大型企业级应用,React都为开发者提供了灵活且高效的工具。然而,想要真正优化React应用的性能,仅仅掌握组件和状态管理是不够的,更需要深入理解React背后的调和(Reconciliation)算法。调和算法是React用来高效更新用户界面的核心机制,它决定了React如何根据数据变动智能地更新DOM,从而为用户呈现最佳体验。本文将全面剖析React调和算法的工作原理、关键概念以及在实际开发中的应用策略,帮助开发者掌握提升性能与优化架构的秘诀。首先,调和算法的核心任务是将React组件树的最新状态与先前状态进行对比,找出差异部分,继而以最小代价更新真实DOM。
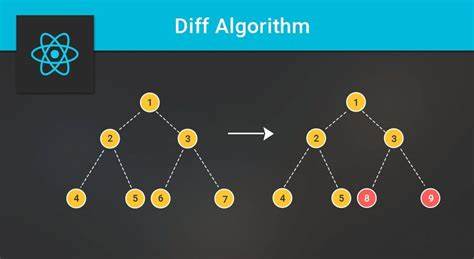
这种策略极大地提升了性能,因为DOM操作相对昂贵,减少不必要的重绘和重排直接影响页面响应速度。React通过构建虚拟DOM(Virtual DOM)或者更准确地说,元素树(Element Tree),来完成这一过程。元素树是React组件渲染结果的轻量级表现形式,每一个节点都是一个JavaScript对象,包含了组件类型及其属性。React在每次状态更新时,都会重新生成一棵新的元素树,并与上一次的元素树进行对比。调和算法的第一条原则是“元素类型决定身份”。当React发现当前元素与之前元素类型不同时,会选择销毁旧树的相关部分,重新构建新的元素节点。
例如,当列表中的某个元素类型由<div>变成了<span>时,React不会尝试复用旧的DOM节点,而是完整替换。这保证了界面的一致性,也避免了潜在问题。其次,调和算法重点依赖于元素在树中的“位置”来判断身份。组件或元素在父节点中的索引被视为其主要身份标识。基于位置的对比使得React能高效针对同类型元素进行属性更新,而非重新创建。例如在条件渲染中,如果组件类型不变但参数发生变化,React会更新组件的props而保持内部状态。
然而,这种依赖位置判断的方法存在限制,尤其在列表顺序频繁变化时,元素的位移会导致组件被重复卸载和重建,状态丢失。为了解决这一类问题,React引入了“key”机制。key是开发者在渲染元素时赋予的独特标识,React用它替代天然的索引,有效区分同一层级中的节点。合理使用key能让React准确跟踪元素身份,从而保持组件状态,减少不必要的DOM操作。尤其在动态列表或复杂的组件条件切换中,key的正确使用提升了页面整体性能和稳定性。例如,切换标签页时,为激活的用户资料组件指定固定key,React便能保留其状态和输入内容,带来更自然的用户体验。
在调和机制之外,React的组件设计和状态管理策略也深受调和算法影响。开发者应尽量避免定义嵌套组件、滥用状态提升或在过高层级统一维护过多状态。合理的组件结构不仅让调和过程更加顺畅,也减少了无效渲染。将状态定位于最小粒度的相关组件,实践“状态共置”模式,有助于缩小更新范围,提升应用响应效率。与此同时,组件职责分离,确保每个组件聚焦单一功能,有助于避免因任何一个状态变化而触发整个页面的重绘,增强应用的可维护性和扩展性。除了调和基本机制的理解,掌握配合React提供的工具也至关重要。
React.memo能够基于props浅比较防止组件不必要的更新,但其底层仍是依赖调和算法的元素对比。如果组件设计本身未遵循调和原则,memo效果有限。细致理解调和过程,辅以合适的key和状态策略,才能发挥memo的最大优势。此外,将非关键UI逻辑拆分成纯函数或自定义hook,也有助于减少渲染开销,加强代码复用和清晰度。调和算法和React设计哲学完美契合,它体现了单一职责原则、接口隔离以及依赖倒置等软件工程核心理念。每一个被渲染的组件都应有明确职责,避免混合业务和展示逻辑,从而减少因小范围状态改变而引起大面积更新的隐患。
同时,借助key和组件类型的组合,开发者可以灵活微调UI表现,实现复杂交互的流畅切换。总之,如何驾驭React调和算法,是每个React开发者实现高质量、高性能应用的必修课。理解元素类型、位置与key在调和识别中的作用,合理规划组件边界和状态分布,避免滥用状态提升和嵌套组件,将会极大提升代码效率和用户体验。未来的React项目中,借助这些原则设计的组件架构,将更易维护,更具扩展性,同时保持极佳的运行性能。面对日益复杂的前端需求,深刻把握调和的内核机制,不仅能让我们写出更高效的代码,更能让应用的每一次渲染都更加精准优雅。