在当今人工智能领域,基于Transformer架构的大型语言模型(LLMs)正在引领革命性变革。然而,随着模型参数量和上下文宽度的爆炸式增长,硬件资源,尤其是显存(VRAM)成为模型运行的“隐形瓶颈”。在生成式推理过程中,K/V缓存体系的内存占用常常高得惊人,快速增长的上下文长度更让这一问题加剧。于是,如何高效压缩KV-Cache(Key/Value缓存)成为研究和工业界关注的焦点。MLA(Multi-Head Latent Attention)技术应运而生,通过核心的低秩投影和按需解压机制,展现出极具创新性和实用价值的解决方案。MLA不仅延续了注意力机制的表达能力,还为显存受限环境下模型推理打开了新天地。
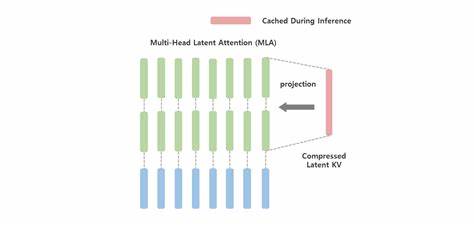
传统多头自注意力机制中,模型会为每一个输入Token及其注意力头单独生成对应的Key和Value向量。具体来说,如果序列长度为L,头数为h,单头维度分别为d_k和d_v,那么KV缓存的总规模大约是L×h×(d_k+d_v),随着序列长度线性增长,显存消耗也随之暴涨。交换至分布式多GPU架构时,通信带宽和延迟不堪重负,阻碍了长上下文场景的落地。多查询注意力(MQA)和分组查询注意力(GQA)等方法尝试通过不同程度地共享头间K/V向量,来缩减KV-Cache存储,虽然在一定程度上降低了显存需求,但却存在共享过度导致头部多样性丧失、对模型性能产生负面影响的风险。相比之下,MLA的突破在于从根本上改变了KV缓存的存储策略。它不是简单地共享K/V向量,而是引入了低秩投影,将每个Token的高维多头K/V转换为一个维度远小于原始维度的latent向量。
换言之,MLA用一个紧凑的“潜在表示”取代了冗余的数据存储,将复杂的多头K/V信息蕴藏于极简的低维空间中。这个潜在向量在推理时可以通过特定的线性变换,动态还原成各个头对应的Key和Value向量,实现按需动态解压。通过这种设计,模型在推理阶段只需缓存低维latent向量,大幅压缩KV-Cache占用,同时保留了多头注意力的表达丰富度。此过程中的矩阵合并技巧进一步减少了数据读取和运算的负担,加速了推理速度。举例来说,当模型维度为4096,头数为32,每个头Key的维度为128时,传统多头缓存每Token需4096维的存储,MLA则可以用512维latent向量替代,达到了约8倍显存压缩。更为重要的是,MLA巧妙地兼容了RoPE(Rotary Position Embedding)等相对位置编码机制。
绝大多数Transformer模型依赖RoPE增强位置感知能力,但RoPE的旋转变换对K/Q向量构造带来了复杂的影响。MLA通过对latent向量与RoPE编码进行分段管理,设计了“潜在部分”和“小规模位置部分”结合的方案,确保相对位置信息不受压缩影响,实现了精准的时空编码与记忆容量的平衡。为更通俗理解MLA机制,可将其比作存储“照片相册”的智能压缩方案。传统方法是为每张照片(Token)保存原图及多种滤镜(不同头的K/V),占用空间大且重复。而MLA则像是为每张照片保存一张低分辨率但信息完整的缩略图(latent向量),而滤镜则在浏览时动态生成,既节省了存储空间,也提升了查询效率。显然,这种设计理念对提升长文本推理中的内存友好性至关重要。
MLA不止是在理论上实现了KV-Cache压缩,其在实际系统中的工程应用也卓有成效。例如,深度学习框架中通过专门设计的缓存管理和权重矩阵合并机制,MLA成功将数千甚至上万Token的上下文加载进单张GPU显存,极大提升了模型的推理上下文长度和吞吐率。有研究和产品线已经采纳了MLA方案,推进了大规模语言模型在聊天机器人、文档理解、代码生成等领域的落地与扩展。此外,MLA在数值稳定性、混合精度训练兼容性方面也表现优异。虽然低秩投影和矩阵乘法的顺序调整可能带来微小误差,但通过合理设计精度保留和回退机制,基本满足精度敏感应用需求。对于开发者而言,MLA的关键在于合理配置latent向量维度和RoPE位置维度比例。
在具体任务和模型规模不同的场景中,需要通过经验调优找到最优折中——较小的latent维度有助于节省显存,过小则有损表达能力;而RoPE维度不足可能影响长距离依赖建模。展望未来,MLA理念有望与最新的注意力优化方法融合,形成更加高效灵活的推理解决方案。其低秩潜在向量的思想也可拓展至其他相对位置编码,比如ALiBi、NTK Scaling,甚至适配多模态Transformer架构。综上所述,MLA通过巧妙运用低秩投影和动态解压策略,颠覆了传统KV缓存的设计范式,实现了巨幅显存削减与性能提升的双重目标。它为大规模上下文推理打开了通向更长序列、更快速响应的崭新道路。理解与掌握MLA不仅有助于推动深度学习模型架构革新,也为工程师在硬件资源有限的条件下探索语言模型应用提供了强有力的技术支持。
随着技术生态和开发工具的完善,MLA必将在大模型领域发挥愈加关键的作用,引领AI推理进入更高效、更智能的时代。









