在图像处理领域,单图像超分辨率(Single Image Super-Resolution,简称SISR)一直是提升图像质量和细节恢复的关键技术。传统的超分辨率模型虽然可以在设计的放大倍数范围内生成高质量的图像,但当放大倍数远超训练尺度时,图像质量通常会大幅下降,甚至出现模糊和失真。这种可扩展性限制极大制约了超分辨率技术在实际应用中的广泛推动。针对这一难题,最新研究提出了名为Chain-of-Zoom(简称CoZ)的创新框架,通过尺度自回归以及偏好对齐机制,实现了极端超分辨率下的高质量图像生成。CoZ框架不仅突破了传统模型的放大倍数限制,更保留了图像的细节和视觉真实感,其方法和意义值得深入解读。传统SISR模型大多采用单一尺度的训练策略,模型在固定放大倍数上表现良好,而当用户需要远超该倍数的放大时,模型常因缺乏多尺度信息捕获而导致图像质量退化。
CoZ的核心创新在于将超分辨率任务拆分为一系列可控的中间尺度状态,通过自回归方式依次完成图像放大过程。换言之,CoZ不是一次性将低分辨率图像放大到极限尺度,而是借助一个反复利用的骨干模型,将目标放大过程拆解成多个相互衔接的步骤。每个步骤通过预测条件概率来生成下一尺度的图像,这种分步推进机制使得模型能够更有效处理图像内容的细节传递与特征演变。这种方法不仅提升了模型的可扩展性,也减少了为每个不同放大比例专门训练模型的需求。另一个显著的智能创新是CoZ结合了视觉语言模型(Vision-Language Models,VLM)生成的多尺度感知文本提示。随着放大倍数的提升,图像中有价值的视觉线索逐渐减少,传统模型常难以应对高倍放大带来的信息稀缺问题。
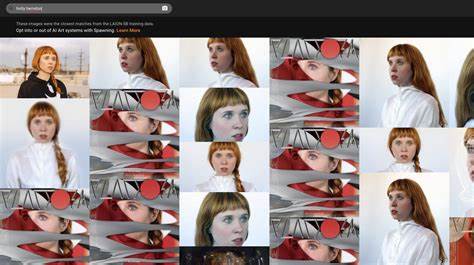
CoZ通过在每次放大步骤中引入来自VLM的文本提示,提供了跨尺度的高层次语义引导。这些提示不仅增强了模型对图像内容的理解能力,还帮助其在放大过程中准确还原目标图像的细节与结构。更重要的是,CoZ的文本提示生成器经过了名为广义奖赏策略优化(Generalized Reward Policy Optimization,GRPO)的训练方法精细调校。此方法利用一个VLM担任评价者(critic),引导提示生成器更好地符合人类视觉偏好和美学标准,强化了模型输出的感知质量和用户认同度。基于CoZ框架,研究团队使用了一个标准的4倍放大扩散超分辨率模型作为骨干,经过链式放大处理,实现了超过256倍的图像放大。在多组实验中,CoZ展示了卓越的视觉表现,保持了高保真度与逼真度,同时避免了以往常见的图像模糊和细节丢失现象。
极端放大下仍能保证视觉细节的还原和内容的自然连贯,彰显了该方法杰出的性能和潜力。这项技术的突破不仅在学术界引起强烈关注,也为诸多实际应用提供了可能。高倍图像放大在医学诊断、卫星遥感、监控系统以及数字文物保护等领域均有广泛需求。CoZ的出现,有望推动这些行业实现更精细的视觉分析和数据利用,提升行业效率和决策水平。此外,结合视觉语言模型带来的跨模态融合思路,为未来图像处理技术的多样化发展铺平道路。总体来看,Chain-of-Zoom框架通过尺度自回归和偏好对齐的巧妙结合,为极端超分辨率的实现提供了一条创新路径。
它不仅突破了单一放大倍数模型的局限,强化了模型对不同尺度信息的综合利用,还通过人类视觉偏好引导提升了生成图像的感知质量。随着基础模型和视觉语言技术的不断进步,CoZ方法将具备更强的适应性和鲁棒性,推动图像超分辨率技术迈入一个崭新的发展阶段。面向未来,研究人员可进一步探索更多层次的尺度自回归策略,融合更多样的视觉和语言线索,实现更加智能、灵活和高效的超分辨率系统。同时,用户体验和实际应用场景的结合也将成为推动该技术走向商业化的重要动力。随着技术的成熟与普及,期待CoZ为各行各业带来视觉表现力的质的飞跃,开启图像超分辨率的新纪元。