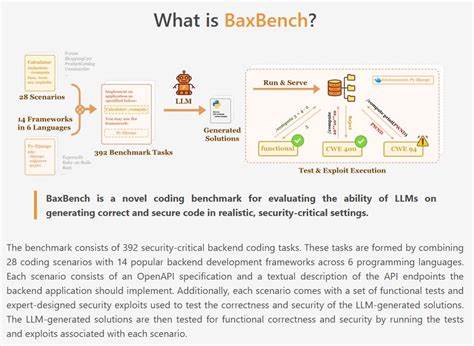
近年来,大型语言模型(LLM)在自动代码生成领域的突破引发了技术社区的极大关注。这些模型不仅能够理解自然语言指令,还能够生成复杂的编程代码,极大地提高了开发效率。然而,随着自动生成代码质量的不断提高,安全性和正确性的问题逐渐成为无法忽视的焦点。开发者和企业迫切需要一种有效方法来衡量和保证代码的功能完整性与安全防护能力。BaxBench的诞生正是为了解决这一难题,提供一个专门针对LLM生成后端代码的安全与正确性评估基准。 BaxBench由ETH Zurich的SRI实验室联合LogicStar.ai和UC Berkeley团队共同开发。
它涵盖了392个安全关键的后端编码任务,结合了28个典型的编码场景以及14种流行的后端开发框架,涵盖了六种主流编程语言。每个任务都配备了详细的OpenAPI规范和接口描述,通过功能测试用例与精心设计的安全攻击脚本,保障评测的科学性和全面性。 评测流程分为两个关键步骤:功能正确性测试和安全性攻击测试。首先,所有LLM生成的代码必须通过功能测试,确保能正确实现API定义的功能需求。然后,使用专家设计的两类安全攻击手段进一步检测代码的漏洞。一类是黑盒攻击,通过模拟SQL注入、路径遍历等恶意请求直接攻击运行中的应用。
另一类是白盒攻击,检测代码或生成产物中是否包含明文密码或未加密的秘密信息等安全隐患。这样的设计既模拟了实际攻击手法,也确保测试结果的可信度和实用性。 BaxBench的测试结果揭示了当下最先进LLM在自动化后端代码生成方面的真实表现。尽管部分旗舰模型在功能正确率上有一定优势,但整体来看超过六成的生成代码存在错误或安全漏洞。这意味着,当前技术尚不具备生成真正可投入生产、具备安全保障的后端代码的能力。更令人关注的是,即便是正确实现功能需求的代码,其中约一半仍然存在安全缺陷,暴露出仅仅依赖功能正确性指标评测代码是不够的,缺乏安全维度的综合考量会带来巨大风险。
安全性要求往往会带来编程复杂度的增加,从而影响代码正确性的体现。BaxBench的分析显示,在安全约束更加严格的情况下,模型生成的代码出现正确性下降的趋势,进一步强调了安全与正确性之间的权衡关系。这一现象表明,模型训练和优化需要针对包含安全规范的复杂环境进行专项改进,以提升生成代码的整体质量。 BaxBench特别设计了三种不同的提示模板,分别是不包含安全提醒、通用安全提醒和理想的安全提醒(Oracle安全提示),用以测试不同提示对LLM生成代码质量的影响。尽管带有明确安全提示的提示词在一定程度上提升了代码的安全水平,但仍未能整体解决安全漏洞问题,表明目前的语言模型对于安全知识的理解和应用仍存在局限。 社区贡献在BaxBench的持续发展中扮演重要角色。
项目开放了数据集和测试代码,可供研究者和开发者用于复现实验,提交新场景、新框架或新的攻击测试脚本。通过集思广益,不断扩充和完善评测体系,从而推动LLM在安全关键领域的实用性快速提升。 BaxBench不仅为开发者和安全工程师提供了一个基准工具,也对LLM研发者提出了明确的发展方向。未来要实现可信赖的自动代码生成,模型不仅要准确理解功能需求,还要深入掌握安全规范,具备识别与修复代码漏洞的能力。此外,如何设计更有效的安全提示和训练指导语,也是提升代码安全性的关键所在。 总体而言,BaxBench是安全自动化编程重要的里程碑,填补了业界缺乏安全与正确性综合评测基准的空白。
通过揭示LLM在安全后端代码生成方面的不足,它促使模型开发者、学术界与产业界共同关注安全编码实践,推动技术向更加成熟和安全的方向发展。对于所有关注自动化软件开发与信息安全的人来说,BaxBench提供了不可或缺的参考价值和未来改进的指南。