PyTorch作为当今最受欢迎的深度学习开源库之一,凭借其简洁友好的接口和强大灵活的功能,成为人工智能研究与应用的首选。对于刚接触深度学习和PyTorch的新手而言,理解其核心组件和基本用法非常重要。本文旨在用简明易懂的语言带领大家在短时间内掌握PyTorch的精髓,从张量基础知识讲起,逐步深入到训练深度神经网络、使用GPU加速计算,进而到多GPU分布式训练的实操细节,让读者能够快速上手并高效利用PyTorch构建复杂模型。 深入理解PyTorch的第一步就是从张量(Tensor)说起。张量是PyTorch的核心数据结构,类比于NumPy中的数组,但张量支持在CPU与GPU间无缝切换,实现高效的并行计算。张量能够表示标量、向量、矩阵乃至更高维的数据。
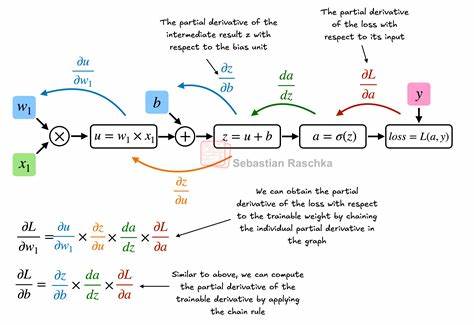
PyTorch中创建张量非常简单,可以由Python的列表或数值直接转换,且不同数据类型的张量(如int64、float32)能够满足不同计算精度的需求。张量除了存储信息外,还支持丰富的数学操作,包括转置、相乘、重塑、索引等,这些操作构成了我们深度学习过程中对数据的基本处理手段。 PyTorch的第二个核心组件是自动微分引擎autograd。深度学习的核心是通过反向传播算法实现模型参数的优化,关键在于计算损失函数相对于参数的梯度。传统上,手动推导和编写梯度计算繁琐且易错,而PyTorch通过自动构建计算图,动态追踪张量上的操作,实现了无需手工求导的高效梯度计算。具体来说,当张量被设置requires_grad=True时,PyTorch会自动记录对该张量的所有操作,生成有向无环图。
调用.backward()方法时,autograd会反向遍历计算图,自动完成链式法则的梯度累积,从而极大简化了模型训练代码,实现高性能的梯度计算。 在此基础上,利用PyTorch的神经网络模块(torch.nn),用户可以快速定义多层神经网络模型。其设计理念是通过继承Module类,将神经网络的层次结构抽象成组合的模块,模块间通过forward方法实现前向传播。利用Sequential容器,更可以简洁地堆叠线性层、激活函数等组件,方便搭建多层感知机、卷积神经网络等常见结构。模块化设计让参数的管理、保存和加载都异常高效,同时与autograd无缝结合,保证了训练更新的完整性和便捷性。 数据加载环节同样重要,PyTorch提供了Dataset和DataLoader模块以支持灵活、高效数据输入。
自定义Dataset接口时,需要实现__getitem__和__len__方法,明确每条数据的获取方式及总样本数量。DataLoader则负责批量采样、随机打乱以及多线程并行加载等功能,极大提升了训练过程的数据预处理效率。通过合理设置batch_size、shuffle、num_workers等参数,能够减少CPU数据准备成为GPU训练瓶颈的可能,保证深度学习训练流水线的最高效率。 训练循环是整个深度学习流程的核心。标准的PyTorch训练步骤包括将模型切换到训练模式、遍历数据加载器按批次取数据、前向传播计算模型输出和损失、清空梯度、反向传播计算梯度、利用优化器更新参数等。此外,训练和推理模式的切换通过model.train()和model.eval()控制,确保诸如Dropout和BatchNorm等层根据需求表现正确。
损失函数和优化器的合理选择及超参数调整直接影响模型表现。训练结束后,模型的状态字典(state_dict)可以保存到磁盘便于后续加载复用。 借助GPU计算,PyTorch能够显著提升大规模神经网络训练速度。将张量和模型迁移至GPU只需要调用.to(device)即可,其中device可通过torch.device("cuda" if torch.cuda.is_available() else "cpu")灵活指定。需要注意的是,所有参与计算的张量必须位于同一设备,否则执行操作会报错。GPU加速尤其适用于计算密集型任务,如卷积运算、矩阵乘法等,能有效缩短训练时间,提升实验迭代速度。
针对拥有多块GPU的先进计算环境,PyTorch的DistributedDataParallel(DDP)框架提供了简单高效的分布式训练方案。在DDP中,每个GPU运行独立的进程,加载模型副本,并且分配非重叠的数据子集。每次迭代时,所有GPU独立完成前向与反向传播,然后通过高速通信接口同步梯度,确保模型副本权重一致。DDP不仅提高了训练速度,更降低了单个GPU显存压力,支持超大模型训练。配置DDP涉及初始化进程组(init_process_group)、利用DistributedSampler合理划分数据、用DDP包装模型等步骤。需注意DDP不适合直接在Jupyter等交互式环境运行,推荐以python脚本搭配torchrun或torch.distributed.launch调用执行。
总结来看,PyTorch基于张量构建计算,结合自动微分和神经网络模块,为深度学习提供了灵活且高效的开发框架。数据加载机制和训练循环设计直观清晰,支持单机单卡、多卡及分布式多卡训练,满足不同规模任务的需求。借助GPU加速,开发者能在合理的时间内完成复杂模型训练,推动AI应用快速落地。初学者应重点掌握张量操作、计算图与反向传播原理、模型搭建以及训练流程,要不断实践以加深理解并灵活应用于实际问题中。同时,关注PyTorch官方更新和社区资源,跟进新特性和优化,持续提升技能。未来深度学习的复杂性和规模不断增长,PyTorch作为行业领先工具,其强大的易用性和扩展性仍将助力科研与工业界取得更多突破。
。