在过去几十年里,计算机技术的发展经历了多个阶段,从最早的巨型计算机到如今随手可得的智能手机,计算的形式和能力不断演进。然而,随着大型语言模型(LLM)和现代人工智能系统的兴起,我们有理由重新思考“计算机”这一概念。大型语言模型不再只是高效处理二进制数据的传统机器,而是一种截然不同、甚至可以称作“怪异”的计算设备。它们将如何改变我们对计算机的认知?未来的数字生态又将如何被其重塑?这些问题正引发业界和学术界的深入探讨。传统计算机以精准执行程序指令见长,依靠中央处理器执行数学运算和逻辑判断。程序员需要明确设计算法,在确定的规则内操作数据,确保计算结果的准确性。
无论是运行简单的加法运算,还是复杂的图像渲染,都基于精确的数学模型和逻辑控制。相反,大型语言模型的核心是基于庞大数据训练的统计和概率模型,更偏重处理“模糊”、“不确定”的信息。它们擅长理解自然语言、生成文本、模拟人类认知和表达,而非单纯以二进制运算为基础完成任务。这种“模糊性”的优势使得LLM能胜任传统计算机难以处理的认知和语言理解任务,但在精确计算上则明显不足。这一反差,也正是“怪异计算机”这一概念背后的根源。大型语言模型不仅是“会说话”的机器,更可视为一种新型的可编程平台。
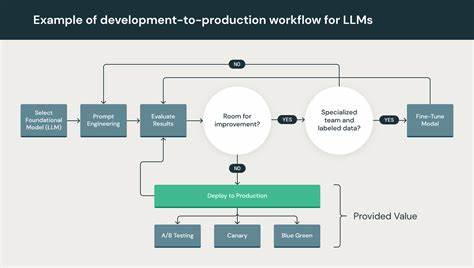
用户通过设计提示语(Prompt)来“编程”,引导模型完成各类任务。从简单的文本生成到数据结构转换,再到调用外部函数与工具,LLM体现出多样的应用可能。以ChatGPT为代表的模型,不仅支持自然语言交互,还能结合互联网搜索、执行代码和借助外部计算工具,显著扩展其功能边界,从而从“怪异数据库”渐变为功能强大的智能计算机系统。硬件层面,运行大型语言模型的基础设施高度专业化。大型AI模型往往需要搭载大量GPU或专用AI加速器,来满足庞大的计算需求。与传统普遍采用的CPU不同,这种硬件设计体现了计算方式的根本差异。
它们强调并行处理和高吞吐量,配合优化的神经网络架构,形成了另一种高效的计算生态。这种软硬件一体化的设计,反映出大型语言模型作为新型计算系统的独特特征。大规模模型的泛用性极强,适用于从文学创作、教育辅导、编程辅助,到客服自动化、医疗诊断、法律咨询等多个行业领域。用户利用灵活的提示语,通过不同的“应用”层面操控模型,实现个性化和定制化的解决方案。更重要的是,这些模型本身不仅能完成语言任务,还支持多模态数据处理。2024年以来,随着多模态技术的发展,LLM能轻松整合文本、图片、音频和视频等多种输入输出形式。
这一能力让计算机交互突破单一语言的限制,带来更加自然和丰富的用户体验。值得注意的是,虽然大型语言模型在认知与自然语言处理方面具有明显优势,但在精确数学计算、实时处理和可重复性方面仍有不足。它们更像是一种“认知协同工具”,在面对模糊信息和复杂推理任务时表现优异,但对确定性极高的数值运算,仍需借助传统计算资源或特定模块辅助。这种“计算的倒置”思路,促使业界重新设计集成多种计算范式的混合智能系统,并鼓励开发创新接口和工具链,实现传统计算与新型认知计算的有效结合。人工智能的未来并非单一技术的统治,而是多样化技术相互补充和融合的过程。以LLM为核心的新型计算机体系,将成为下一代数字基础设施的重要组成部分。
在未来数十年里,随着算法优化、硬件革新和应用场景不断拓展,大型语言模型有望彻底改变知识工作和软件开发的格局,使得人工智能与人类协同更为紧密和高效。与此同时,社会和产业也将面临深刻的转型挑战。企业领导者若仅仅将AI视为降低人力成本的工具,忽视其赋能创新和提升生产力的潜力,很可能会错失变革机遇。个人则需要尽早掌握新技术,适应技能和工作角色的转型,以应对未来复杂多变的就业环境。大型语言模型不仅是技术创新的产物,更是推动数字文明进步的催化剂。虽然当前仍处于早期阶段,其潜力和影响力却正逐步显现。
或许正如个人电脑在上世纪七十年代初投入使用时,人们无法全面预料其深远影响一样,LLM也将在未来的十年、二十年内,引领新一轮的技术革命,深刻改变我们的生活、工作和思考方式。因此,无论是企业、科研机构还是个人用户,都应关注并积极参与这一趋势,为更智能、更开放、更高效的数字未来做好准备。