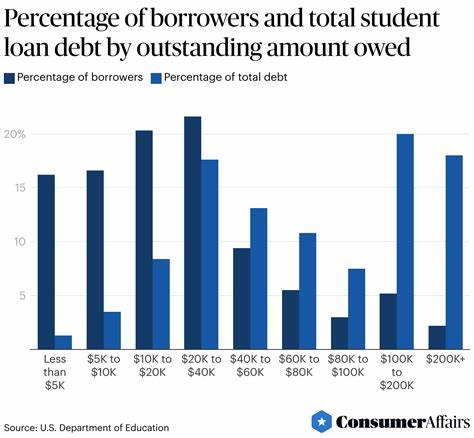
在现代计算机科学中,正则表达式作为文本匹配的重要工具,已经渗透到各种编程语言和系统中。在实现高效的正则表达式匹配过程中,有限自动机(Finite Automata)及其两种主要形式——确定性有限自动机(DFA)与非确定性有限自动机(NFA)扮演了关键角色。NFA的一个鲜明特征便是其支持ε转移(epsilon transitions),这一机制虽然在理论上早已被广泛研究,但在实际编程实现及性能优化中仍存在许多值得深究的细节。本文将围绕ε转移进行系统阐述,结合作者在开源项目Quamina中的实践经验,揭示这一概念的应用与挑战。 有限自动机作为状态机的重要类型,能够对输入字符串逐字符进行状态转换。DFA由于其从一个状态到下一个状态转换是确定的,每读取一个输入符号便有且仅有一个确定的转换路径,因而实现简单但在复杂正则表达式处理时存在状态爆炸问题。
相对而言,NFA允许在某一状态接收一个输入符号时,转换到多个状态,甚至包含无需读取输入就能发生的ε转移。所谓ε转移,即允许自动机在任意时候在状态之间跳转而不消耗任何输入符号,这为实现正则表达式里的特殊操作符,如“*”、“?”和“.”等提供了理论基础。 在传统的正则表达式NFA构造方法中,Thompson构造法被广泛采用。该方法以其系统化、模块化的特点,将复杂的正则表达式分解为简单的基础表达式,逐步构造对应的NFA片段,并通过ε转移将这些片段有效组合。利用Thompson构造,正则表达式中的零次或一次匹配(用“?”表示)可通过在两个状态间设置一条带输入符号的转移和一条ε转移实现,从而保证无论是否匹配输入符号,都能顺利过渡到后续状态。这种灵活的转移方式极大增强了表达式匹配的表达力与实现的简便性。
理解ε-闭包(ε-closure)是掌握NFA遍历的关键。它指的是从一个状态出发,通过所有可能的ε转移能到达的一整组状态集合。换言之,计算ε-闭包是确定在不消耗任何输入的情况下,自动机实际可以处于哪些状态。该操作在实现NFA匹配算法时尤为重要,因为每次读取输入符号之前,都必须先计算当前活跃状态集合的ε-闭包,使得所有基于ε转移的状态转换被“激活”以便正确响应输入。举例来说,对于表达式A?B?C?X,其对应NFA初始状态的ε-闭包包含了所有可能忽略A、B、C的状态,这样输入不同组合符号时,状态机能够灵活切换到正确的后续匹配状态。 然而,ε-闭包的计算并非没有挑战。
尤其在包含循环回路的正则表达式中,如(A+BC?)+,计算ε-闭包时如果不加控制,极易陷入无限循环,因为状态间的ε转移可能形成闭环。此时对已访问状态的跟踪成为必需,以防止重复进入同一状态。实际应用中,维护访问标志通常需要额外内存分配,这对高性能需求的场景,如Quamina项目中处理每秒百万级事件的正则匹配,产生了明显的性能压力。针对这一问题,缓存已计算的ε-闭包结果成为一种常见优化策略,有效减少重复计算,提高匹配效率。 此外,传统NFA定义中,状态在接收输入符号时可以转移到多个状态,这种“多分支”转移实际可以完全用ε转移模拟。作者在实践中提出了一种简化NFA结构的方法,通过引入“splice”状态,将多个同输入的转移路径先通过ε转移汇集,再由“splice”状态单一决定后续状态走向。
该方案不仅数学上等价,而且提高了实现简洁性和遍历逻辑的统一性。实际上,Thompson构造法中实现正则表达式的“|”操作正是基于该“splice”机制,这为理解和设计NFA结构提供了思路同时也帮助避免了冗余状态的产生。 实现高性能NFA遍历算法时,除了关注ε-闭包的正确计算,状态集合的管理尤为重要。每读取一个输入符号,算法需要将当前状态集合展开成所有可能的ε-闭包状态,再试图在这些状态中匹配输入符号转移,新的状态集合则成为下一轮处理的基础。这样的迭代使得算法能够在复杂表达式和长输入串中保持正确的匹配路径。尽管在理论上每一步都较为简单,实际系统中维护大量状态集合和避免重复状态导入了额外复杂性,尤其是在内存和时间资源有限制的场合。
正则表达式的强大源自其丰富的操作符和灵活的匹配规则,背后不可或缺的是基于有限自动机的高效实现策略。其中ε转移是连接结构模块、支持任意次数匹配及选择分支的关键机制。深入理解ε-闭包的计算方法及其潜在问题,有助于开发者优化匹配算法,进而在海量数据及频繁匹配需求场景中提升软件的响应速度与稳定性。 未来,优化ε转移相关算法、探索缓存机制的最佳实践、以及平衡内存开销与性能优势,将是正则表达式引擎发展的重要方向。随着实际项目中对正则匹配性能的要求日益提高,如何利用理论与工程结合的方式提升自动机实现效率,依然是技术讨论的热点。 通过本文的系统介绍与剖析,希望对正则表达式实现的研究人员、软件工程师乃至计算机科学兴趣者提供有价值的参考与借鉴,助力正则匹配引擎的持续优化和创新。
。