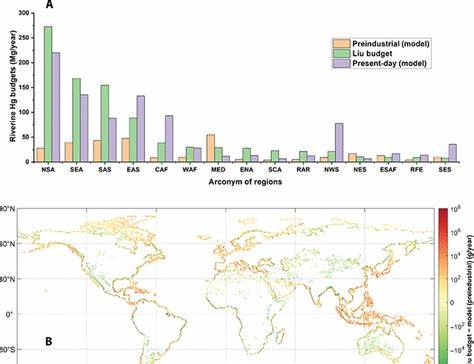
搜索引擎的优化和评估一直是技术团队关注的焦点,尤其是在竞争激烈的数字环境下,如何判断搜索结果是否达到了预期效果更是关键。近年来,复杂的指标和评价体系层出不穷,诸如NDCG等量化指标常被视为衡量搜索质量的标准,但它们真的适合所有团队和场景吗?本文将从一个更为直接和实际的视角解读搜索评估的本质,提出所谓“原始智能”(Grug-Brained)搜索评估方法,帮助大家聚焦于真正重要的质量提升路径。首先需要明确,任何衡量搜索结果的指标,本质上都是一种针对目标的量化尝试。搜索引擎评估中,NDCG(Normalized Discounted Cumulative Gain)一直以来被广泛使用作为衡量搜索结果排序优劣的标准,它通过标注查询结果的相关性,并计算排名分布来反映整体效果。理论上,NDCG值越接近1,代表用户获得的结果越符合预期,1代表完美的排序状态。然而,这种评价方法虽然科学,但在实际应用中存在诸多难题。
标签数据的质量是限制NDCG指标有效性的根本。为每一个查询单独标注结果相关性,不但耗费大量人力资源,而且容易产生偏差。标注者往往不能完全代表真实的用户需求,甚至会带有主观色彩,导致结果不准确。人工疲劳和认知偏差也会影响标注质量。此外,所谓的“关键意见领袖”(HIPPO),即企业内部有影响力但未必了解用户的决策者的判断,可能导致偏离用户真正意图的标注标准。更进一步,用户的点击行为复杂且多样,由界面设计、位置偏好、内容刺激性等外部因素影响,点击数据反映的行为未必等同于准确的相关性,这使得基于点击流的模型同样存在偏差。
对长尾查询的评估尤为困难。长尾查询往往请求量小,用户交互数据稀缺,这限制了基于大量数据统计的评价方法的有效性。为了排除或减少评价误差,团队通常不断投入更多资源,构建更为复杂的模型和体系,但复杂度的提升往往带来新的难题,让错误更难被发现和纠正。面对这些挑战,回归到“原始智能”的评估思路,便是从实际业务需求和预设目标出发,聚焦于“改变是否实现了预期效果”而非追求理想化的“完美”指标。具体方法可以是先明确团队希望改善的查询群体,选择代表性的10-20个查询并进行标注,通过实际调整排名或优化理解过程,观察相关指标是否改善以及旧有查询是否依然稳定。如此一来,评价循环更加简明,能有效避免因过度复杂产生的误导,毕竟评估的核心目的并非告诉我们“好坏”,而是“变更是否达到了预期目标”。
重要的是,理解搜索质量远远不止于排序相关性。一个优秀的搜索体验应包含多样化的结果展示、准确的查询理解、快速响应体感和良好的结果感知等多方面因素。仅依赖NDCG等传统指标,很难覆盖所有维度。因此,真正衡量搜索改进质量的最好路径是结合A/B测试或可用性研究。这些方法能直接对应业务指标,比如销量增长、日活跃用户数提升,或用户问题的解决效率,从而为搜索质量提供最实际的反馈。通过在A/B测试中验证某项调整是否带来正面影响,团队既能确认调整的直接效果,也能洞察整体用户体验改善情况。
与其投入大量精力和预算打造复杂的相关性模型,许多团队更应注重建立持续学习的机制,深刻理解用户真正需求,灵活采用简易且稳健的标注方案,聚焦解决实际问题。当然,在某些进阶场景中,例如打造基于机器学习的排序模型时,需要依赖更为精准和科学的标注体系。这种情况下,获取高质量的标注数据成为关键,可能需要资深数据科学家深入研究点击模型、多层次排名机制和自然语言理解技术。这样的“大脑型”评估方法虽技术挑战大,但对于构建具备长远竞争力的搜索系统不可或缺。然而,技术团队不应盲目追求复杂指标和模型,忽略了简单有效的实践价值。适合自己的评估循环,结合业务目标,采用简单易行的手段,才是推动搜索质量持续向好的关键。
通过保持“原始智能”思维,结合适时的科学投入,搜索团队能够更好地利用有限资源,满足用户需求,推动产品成功。总而言之,搜索评估的核心不在于指标的完美,而在于实现对目标的准确反馈和逐步迭代。通过简化评估流程,聚焦业务导向,辅之以必要的科学建模,搜索系统才能真正做到既符合用户期望,又具备竞争优势。未来,借助大语言模型等新兴技术,结合当地需求精准调整的“原始智能”与“大脑型”方法,必将共同推动搜索体验达到新的高度。