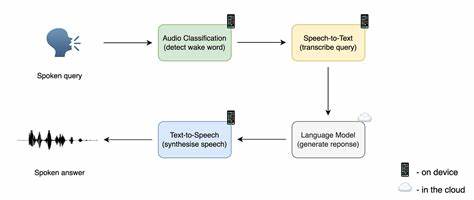
随着人工智能技术的不断进步,强化学习已经成为训练智能体以解决复杂任务的重要技术手段。然而,传统的强化学习方法在面对环境变化时往往需要重新训练或微调,以适应新的动态环境,这不仅增加了训练成本,也限制了智能体的灵活应用能力。零样本强化学习(Zero-Shot Reinforcement Learning)的出现为此带来了变革性的希望,其目标是使智能体在未经过任何测试时微调的情况下,直接部署于新的环境中并表现优异。行为基础模型(Behavioral Foundation Models, BFMs)作为该领域的前沿框架,因其具备多任务学习能力以及理解复杂行为的潜力,成为研究热点。但现实应用中,BFM在动态环境变化面前仍然面临严峻挑战,特别是无法有效处理环境动力学变化引发的表现退化问题。当前研究表明,这一表现退化的根本原因在于所谓的“干扰问题”。
由于训练数据包含了不同环境动态的混合信息,模型难以区分环境差异,导致策略空间的混淆与纠缠,使得生成的策略无法适应新的未见环境。这种问题不仅降低了智能体的泛化效率,也直接限制了零样本学习的实际应用潜力。为了应对这一问题,研究团队提出了一种基于前向-后向(Forward-Backward, FB)策略表示的深入分析,揭示了FB方法在适应动态变化时的局限性。传统FB方法尝试将多个任务或环境的策略表示叠加在同一空间,然而这种做法忽视了环境动力变化在潜变量层面的影响,从而导致策略的双重干扰。针对这一难题,团队提出了两项创新解决方案:信念前向-后向(Belief-FB, BFB)和旋转前向-后向(Rotation-FB, RFB)。这些方法通过引入对环境潜在动态的推断机制,打破了策略纠缠的瓶颈。
BFB方法首先通过轨迹数据推断环境的潜在动态上下文信息,并以此作为条件输入调整策略空间,使模型能够针对不同动力学环境生成更加独立分离的策略表达。这种基于信念的条件化方法有效减少了策略之间的干扰。与此同时,RFB方法则进一步通过调整策略表示空间的先验分布,采用旋转变换来优化策略的表征,使得不同环境动态对应的策略表现更加可区分,进一步强化了模型的泛化能力。这一方法结合了数学上的空间变换理论和强化学习策略优化,显著提升了对未见环境的适应率。团队在多样化的仿真环境中评估了上述方法,包括离散动作空间和连续动作空间的任务,环境配置采用了程序化生成的布局以保证复杂性和多样性。特别是在测试阶段,部分环境完全不同于训练环境,旨在检验模型的零样本泛化能力。
评测结果证实,Belief-FB和Rotation-FB在零样本设置下均表现出显著优势,超越了传统FB模型在策略分离度、学习稳定性及障碍规避效率方面的表现。尤其值得关注的是,新的方法在生成基于环境布局的策略行为上更为准确,能够灵活应对动态障碍,从而展现了强大的环境适应性和策略后备能力。研究中对Q函数的学习和适应进行了深入分析,发现传统FB模型的Q函数难以有效对应动态变化导致的奖励结构变化,而提出的方法通过信念条件化和策略空间分离,使得Q函数能够动态更新并适应不同动力学特征,形成更加稳定且鲁棒的价值评估机制。这不仅提升了策略决策的精确度,也为复杂环境中的实时决策打下了坚实基础。整体而言,零样本行为基础模型的研究不仅推动了强化学习理论的进步,更为智能体在现实世界中应用于多变和未知环境提供了有力支持。未来,基于信念推断和策略空间几何变换的联合方法有望成为提升智能泛化能力的关键路径。
随着算法的不断完善与计算资源的丰富,零样本学习的实际部署前景将更加广阔,涵盖无人驾驶、机器人控制、智能制造等多种领域。对于研究者和工程师而言,深入理解环境动态对策略表现的影响及其解决方案,将有助于设计更加稳健且高效的强化学习系统。结论上,零样本行为基础模型通过创新的信念估计和策略空间调优技术,成功突破了因环境动力变化引起的策略干扰难题,实现了在未见环境中卓越的零样本适应性能。这一进展不仅显著提升了智能体的泛化能力,也为未来强化学习在复杂动态系统中的广泛应用奠定了理论与实践基础。随着技术的发展,期待更多基于此框架的研究将持续推动零样本强化学习的边界,助力人工智能更好地理解和适应现实世界的复杂多变环境。