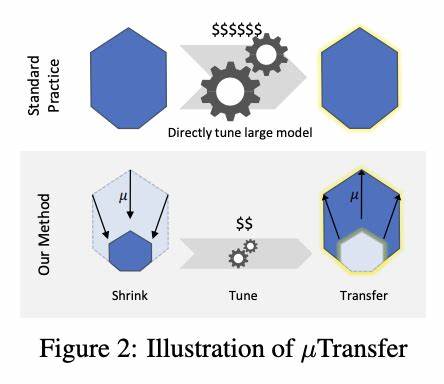
随着人工智能的快速发展,神经网络的规模不断扩大,从数十万参数的小型模型发展到如今数十亿甚至上百亿参数的巨型模型。这些庞大的模型因其强大的表达能力和学习能力,广泛应用于自然语言处理、计算机视觉、推荐系统等领域。然而,大型神经网络的训练和调优依旧面临巨大挑战,尤其是在超参数的设定和迁移方面。传统的超参数调优往往需要反复试验和大量计算资源,导致成本昂贵且耗时漫长。近期,最大更新参数化(Maximal Update Parametrization,简称μP)为这一问题提供了新的解决思路。通过零样本超参数迁移,μP实现了不同规模神经网络间超参数的稳定迁移,大幅降低了调参难度和计算成本,提高了大规模模型的训练效果和泛化性能。
最大更新参数化的核心思想是针对神经网络参数初始化和学习率的调整,保证在模型宽度扩展时,超参数表现稳定且不发生剧烈变化。在传统参数化方式下,随着网络宽度的增加,模型表现对学习率等超参数异常敏感,小幅调整即可导致训练崩溃或性能大幅波动。μP定义了一套“自然”的参数缩放规则,使得训练时每层的激活值、梯度及参数更新幅度都保持在合理范围内,确保模型在不同宽度下表现一致。这种稳定性使得在小规模模型上调优得到的最佳超参数,可以直接应用到更大规模模型中,实现零样本超参数迁移,极大节约了超参数调优的时间和资源。微软研究院提出的mup工具包即基于μP思路,提供了便捷且安全的PyTorch集成方式,帮助研究者和工程师轻松实现这一创新方法。 μP方法的理论基础源自对神经网络训练过程中激活和参数梯度的矩阵向量乘法行为的深入分析。
研究表明,不同类型的矩阵乘法对输出坐标大小的影响存在规律:比如权重梯度矩阵通常表现为外积形式,满足某些梯度量级关系;而参数初始化可视作随机独立同分布的矩阵。这些特性决定了参数初始化和更新时必须采用不同的缩放方式,才能避免梯度爆炸或消失,保证训练动态的稳定性。基于这一理论框架,μP定义了针对参数和学习率的特定缩放规则,使得模型参数更新在扩展到更宽网络时依然合理且高效。 实际应用中,μP不仅适用于简单的多层感知机(MLP)和卷积神经网络(CNN),同样对复杂的Transformer架构表现出良好的兼容性和优越性。Transformer因其在自然语言处理领域的优秀表现而备受关注,但其训练过程异常复杂且对超参数极为敏感。引入μP后,Transformer中的多个维度参数(如模型宽度、注意力头数、前馈层维数)按照μP规则进行缩放,保证了激活尺度和梯度一致性,使得原本脆弱的超参数空间变得稳定。
用户可以在较小模型上快速完成超参数调优,随后通过零样本超参数迁移直接应用至大规模预训练Transformer,实现训练效率和模型质量的双重提升。 mup工具包为实现这一理论成果提供了极大的便利。用户只需定义基础模型(base model)和需扩展的目标模型(target model),并调用相应的设置接口,即可完成μP的参数和学习率自动缩放。该工具还包含对模型参数坐标校验(coordinate check)的支持,以确认μP的正确实现。通过观察不同宽度模型训练初期激活及输出的坐标尺度变化,用户可以轻松发现潜在的缩放问题,保证训练动态的稳定。这个“坐标校验”方法在降低超参数调优复杂度的同时,也使得研究人员能够更深入理解神经网络训练背后的数学结构和动态。
值得注意的是,μP和mup工具在实现中仍存在一些限制。目前该框架假设用户模型是用PyTorch标准初始化方法创建,且不支持某些数据并行范式如torch.nn.DataParallel,推荐使用分布式数据并行torch.nn.parallel.DistributedDataParallel。此外,因为参数缩放会对学习率进行微调,用户自行设计的学习率调度需基于当前调节后的学习率生效,避免覆盖掉μP自动调整的策略。尽管如此,这些限制并不妨碍μP在大规模神经网络调优领域的广泛应用和持续发展。 从更宏观的角度看,μP不仅是一个超参数调优技巧,更代表着神经网络参数空间理解的进步。通过解析激活值和梯度变化规律,μP揭示了不同规模神经网络间的内在联系和训练稳定性原则,引领了超参数设计向更科学和可迁移方向发展。
它打破了以往“重新调参”的顽固模式,帮助开发者实现了多规模模型之间的平滑跳跃和快速试验,不仅节约了计算开销,也加速了模型研发流程。此外,μP思路在未来软硬件协同设计中,也有望帮助构建更高效、可扩展的深度学习系统。 针对于广大深度学习从业者,掌握μP和零样本超参数迁移技术,将成为提升大型模型训练效率的关键。通过实际应用发现,利用μP进行超参数迁移可确保训练过程的数值稳定,有效避免梯度爆炸或减弱现象,进而改善大规模模型训练的收敛速度和最终性能。结合mup提供的易用接口和工具集,用户可以快速在自己的模型框架中集成此技术,降低调试难度。尤其是对于基于Transformer的语言模型预训练和微调,μP无疑提供了革命性的优化路径,助力模型在参数数量剧增的时代依然保持可控和可预测的训练表现。
综上所述,最大更新参数化作为神经网络宽度扩展的一种“自然”范式,为超参数调优领域带来了理论与实践的双重突破。零样本超参数迁移让广大研究者和工程师能够以更低的成本和风险调优大型神经网络,迅速实现从小模型到超大模型的平稳迁移。未来,随着深度学习模型规模的持续增长以及对训练效率的更高要求,μP及相关技术将在模型设计、训练技术乃至资源配置策略中发挥越来越重要的作用。通过深入理解和灵活运用这一方法,机器学习社区将能够更高效地开启大规模人工智能应用的新篇章。









