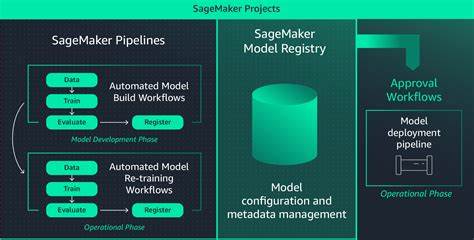
随着人工智能技术的不断进步,机器学习模型的规模和复杂性日益增加,企业对高效、可靠的机器学习运维(MLOps)方案的需求也日益强烈。AWS SageMaker作为云端领先的机器学习服务平台,提供了丰富的工具和服务,支持从模型开发到部署全生命周期的管理。本文基于实际项目经验,结合SageMaker最新的技术动态,深入分享如何构建成熟且实用的MLOps体系架构,以及在不同环境下灵活调整方案的实战智慧。 首先,构建一个成熟的MLOps体系必须明确其关键构成要素。一个完善的机器学习运维流程不仅仅涉及模型训练,更涵盖从开发环境标准化、项目模板准备、自动化流水线搭建、模型注册与管理,到测试验证及监控告警的全方位闭环机制。标准化的开发环境促使团队成员能高效协作,减少因环境差异带来的错误。
通过项目模板快速启动新模型开发,将自动触发训练与部署的流水线,大幅提升开发自动化程度。模型注册中心则负责管理不同模型版本和生命周期,保证模型溯源和安全合规。自动化测试通过性能评估和集成测试确保模型质量。最后,持续监控流程实时跟踪模型线上表现,及时识别数据漂移和性能异常,保障业务稳定运行。 针对不同的业务场景和需求,MLOps的设计思路存在差异。一般而言,可以划分为基础场景和高级场景。
基础场景多用于批量处理或内部系统,模型开发完成后经过本地训练和测试,最终确定版本直接上线生产环境。此类场景相对简单,重点在于模型开发流程的标准化和自动化部署。高级场景则通常涉及复杂的线上验证,如蓝绿发布、金丝雀发布和影子部署等策略。此情况下,往往需要同时部署多个版本的模型端点,进行A/B测试或实时效果比对,以保障用户体验和业务连续性。两者的MLOps流程虽有共通之处,但高级场景需设计更复杂的模型生命周期管理和多版本协调机制。 SageMaker平台对上述需求提供了有效支持。
首先,从代码版本管理入手,推荐采用双主分支策略,包括生产分支和开发分支。数据科学家在特性分支上开发新功能,经本地验证后合并到开发分支,触发模型在开发环境的自动部署。达到质量要求后,将开发分支合并至生产分支,实现模型的正式上线。此分支策略不仅确保代码质量,也有助于搭建流水线自动化触发和环境隔离。 为了加速项目启动和标准化开发流程,SageMaker的项目模板功能尤为重要。项目模板中预置了训练、验证、注册和部署的基础代码框架,数据科学家可以基于模板快速开展工作,避免重复造轮子。
创建项目时,自动生成包含生产和开发代码库的Git仓库及对应分支,同时根据场景自动建立不同的模型组,用于模型版本和分支管理。基础场景常见三个模型组(生产、开发和特性),而高级场景则额外配置冠军和挑战者两个生产模型组,方便进行模型对比和热切换。 项目生命周期管理方面,借助AWS Lambda与基础设施即代码(IaC)工具实现自动化。通常通过Lambda函数响应项目创建或删除事件,自动完成仓库初始化、模板代码复制、分支创建,以及模型组设置等关键步骤。尽管SageMaker标准以CloudFormation管理项目,但在实践中使用Terraform定义Lambda配置,使基础设施管理更加灵活且易于维护。如此一来,团队可以快速响应业务需求的变化,实现高效DevOps闭环。
机器学习流水线是MLOps中的核心组成。基础场景流水线主要包括数据准备、模型训练、模型注册和模型部署几个阶段。开发期间,数据科学家可以选择本地或云端运行管道。通过特性分支提交触发云端训练,完成后模型自动注册到特性模型组。随后决定是否合并到开发分支,将模型迁移到开发模型组,在开发环境部署试用。最终,经过严格测试模型被标记批准,生产分支的部署动作被触发,模型在生产环境上线。
部署端点的启动和停用可通过自动化Lambda函数定时管理,以优化资源使用和控制成本。 相比之下,高级场景流水线在生产阶段增加了多版本并行管理。开发分支到生产分支的合并动作会将模型复制到“冠军”和“挑战者”两个模型组。批准流程对两组模型分别进行触发,形成多端点部署。通过此机制支持蓝绿发布、金丝雀测试等生产级别风险管理策略,确保新模型上线平稳,同时留有快速回滚通道。若采用MLflow作为模型跟踪服务器,还需构建额外的逻辑以监听模型别名变更,辅助实现端点的自动化部署,因托管MLflow服务本身对Webhook支持有限。
模型注册与元数据管理是保证模型可追溯和可控的基础。无论是使用SageMaker Model Registry还是MLflow Tracking Server,都应为每个模型版本附加关键元信息,包括训练所用数据集版本、代码提交ID、超参数及性能指标等。这样可以明确每一次模型训练来源,有效支撑模型审计和再现工作。 测试是保障模型上线后稳定和准确的关键环节。在SageMaker中,QualityCheck步骤可以进行基础模型性能和数据质量的评估。针对没有内置自动化集成和负载测试的缺陷,推荐采用自定义的测试方案。
结合EventBridge事件和Lambda函数,触发模型部署完成后自动执行预定义的集成测试逻辑,并通过DynamoDB存储测试配置,测试结果通过Slack等沟通渠道实时反馈给相关团队。值得注意的是,部分端点类型可能无法生成触发事件,因此需要针对具体情况设计替代触发机制。 模型和数据监控方面,SageMaker Model Monitor提供数据质量、模型质量以及特征漂移监控功能,是机器学习运维不可或缺的工具。使用过程中需要注意,该工具依赖于真实标签数据来评估模型质量,对图像、文本或视频等非结构化数据支持有限,而且监控只能按固定时间间隔执行,缺乏实时连续监控能力。延迟结果也意味着无法即时触发预警。针对资源使用率等技术指标,CloudWatch Endpoint Instance Metrics为管理员提供了基本的运行状态监控手段。
总体而言,SageMaker为构建高效、灵活和安全的MLOps生态提供了坚实基础。从仓库管理,项目模板,到流水线自动化,再到模型注册和持续监控,每个环节均能支持不同层次和复杂度的业务需求。实战经验表明,清晰定义MLOps组件,结合行业成熟的开发策略和自动化手段,是实现机器学习大规模生产的关键。未来,随着AWS不断迭代相关服务,MLOps方案将在智能化、自动化和可视化方面持续优化,进一步简化企业的AI应用部署难度。 以上内容源于在多个实际项目中的沉淀和演进,旨在为机器学习工程师、数据科学家及技术管理者提供一份全面且实用的参考。面对快速变化的AI技术风口,掌握科学的MLOps流程,才能助力企业实现机器学习技术的价值变现,推动数字化转型的深入发展。
希望分享的经验能为您的工作带来启示,促进AI项目的顺利实施和持续优化。