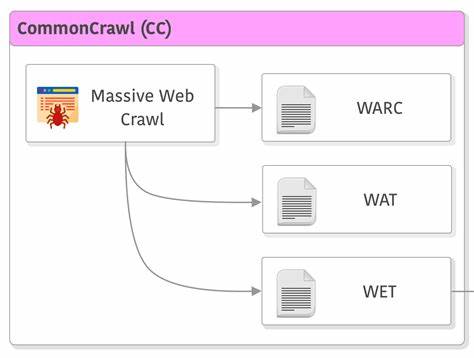
在数字时代,网页内容数量飞速增长,网络爬虫成为搜集和整理这些海量信息的关键工具。Common Crawl作为知名的开源网络爬虫项目,致力于为学术界、企业以及开发者提供免费且丰富的网页抓取数据。然而,尽管Common Crawl已经拥有庞大的数据库,但其语言覆盖仍以英语为主,许多其他语种的内容未被充分收录。为了改变这一现状,Common Crawl基金会正在推动提高其多语言数据覆盖率,力图让更多区域语言和文化得到应有的展示和利用。提升多语言爬取覆盖不仅促进了语言多样性,还为全球机器学习研究提供了多元化素材。自然语言处理(NLP)领域的发展依赖于丰富且多样化的训练数据,而多语言数据的缺乏直接限制了模型在非英语环境下的表现。
通过扩大多语言内容的抓取范围,能够帮助训练出更具普适性和准确性的语言模型,进而惠及全球用户。Common Crawl的多语言覆盖扩展项目面向全球社区呼吁有语言能力的志愿者参与,尤其欢迎掌握除英语以外其他语言的朋友们加入助力。具体参与方式包括验证语言识别数据、贡献网页URL作为种子地址。语言识别(Language Identification)是判定网页或文本片段所用语言的技术,准确的语言识别对于后续数据分类和处理十分重要。项目通过在线平台开放语言识别任务,邀请大家通过验证和标注数据来提升语言识别的精度和覆盖范围。贡献URL也是项目提升多语言爬取的重要途径。
志愿者可以推荐含有不同语言、高质量内容的网页,帮助爬虫更精准地捕捉到相关语言的网络空间。目前,相关的收集链接和工具均在项目的开源仓库中公开,社区成员能够便捷地查看和贡献。此外,Common Crawl还联合MLCommons和EleutherAI等研究组织,共同举办多语言数据质量信号研讨会(WMDQS)以及相关的学术征稿活动,促进跨界合作和研究成果交流。研讨会聚焦多语言数据的收集、识别、质量评估等问题,通过共享任务激励社区创新,为研究人员和数据工程师提供实践平台。多语言数据的拓展对于人工智能领域的多方面发展具有深远意义。在智能搜索、机器翻译、智能问答等应用中,支持更多语言意味着能够满足更多用户需求,促进信息平等和文化交流。
同时,丰富的多语言网络数据有助于减少模型中的语言偏见,构建更公正、包容的技术生态。 Common Crawl的开源理念和社区驱动模式使其成为多语言数据收集领域的典范。通过汇聚全球志愿者的力量,项目不仅实现在技术层面的突破,更促进了全球互联网语言资源的共享。未来,随着参与者不断增加和技术持续发展,Common Crawl将持续提升其数据的多样性和质量,助力全球数字知识库的升级。对于广大开发者、研究者和语言爱好者而言,加入这一项目不仅能够贡献个人力量,也有机会接触前沿技术和跨国研究环境。参与过程中,大家能够深入理解网络数据的结构和语言识别技术的挑战,并推动多语言人工智能的落地。
总而言之,提升Common Crawl的多语言覆盖是顺应全球化发展趋势的重要举措。它不仅推动了互联网内容的多样化和丰富性,也为人工智能和自然语言处理相关领域提供了坚实的数据基础。欢迎更多有语言技能的朋友积极参与,共同打造更全面、多元的网络数据生态,推动数字时代的科技创新与文化交流迈上新台阶。