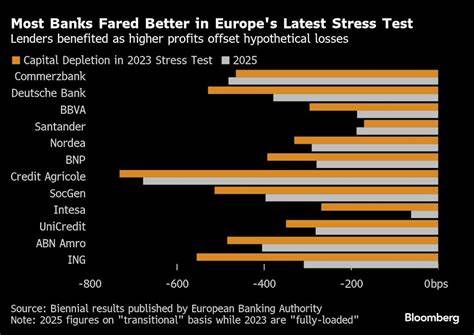
在大数据时代,数据仓库和分析平台的性能表现成为企业竞争力的重要支撑。面对海量数据和复杂联接查询,选择合适的数据库系统尤为关键。ClickHouse、Snowflake和Databricks作为当今最受关注的三大数据处理平台,各自在性能、成本和易用性方面呈现不同特点。本文将深入剖析ClickHouse在联接(Join)操作上的出色表现,结合公开的咖啡店订单数据基准测试,对比分析ClickHouse、Snowflake和Databricks三者性能与成本效益,助力企业更科学地做出技术选型。 ClickHouse作为一款以列式存储著称的开源分析型数据库,近年来通过持续优化联接算法和查询执行策略,刷新了业界对联接性能的认知。此前,部分声音质疑ClickHouse在多表关联场景中的表现,认为其不适合复杂联接查询。
然而,经过近6个月的专注研发,ClickHouse团队发布了涵盖十七条联接密集SQL查询的系列基准测试,结果令人瞩目:无论是7亿多行、14亿行还是72亿行规模数据,ClickHouse均展现了领先的运行速度和成本效率,尤其在无任何调优的“开箱即用”状态下依然保持优异表现。 基准测试背景源自一组仿真国家级连锁咖啡店订单数据,包含销售事实表以及产品和门店维度表,覆盖大量订单与维度间的多表联接查询。测试对比了三大平台在不同数据规模以及多种计算资源配置下的表现。ClickHouse云服务被配置为基于AWS的多个节点集群,开启Parallel Replicas功能,允许多个计算节点并行处理单条查询,从而进一步提升查询吞吐与响应速度。 考察中发现,ClickHouse不仅在最小规模数据集(约7亿条订单)上实现了绝大多数查询时间均不超过1秒,速度比Snowflake和Databricks快3到5倍,且整体计算成本低于竞争对手。随着数据规模放大至14亿及72亿条,ClickHouse依旧展现强劲扩展能力,完成数据联接、聚合和排序等操作的时间分别仅需秒级,远快于其它平台需要的分分钟级时间。
同时,成本控制优势也更加明显,帮助企业降低海量数据分析的总拥有成本。 这一优异表现的关键在于ClickHouse团队对联接执行流程的多方位优化。包括更高效的计划生成减少冗余计算,内存使用智能管理增强系统稳定性,以及针对列式存储结构专门设计的数据扫描与过滤技术。这些改进令ClickHouse能够处理更复杂的联接场景,且不需依赖传统的笛卡尔积规避或额外索引设计,减少设计与维护成本。 此外,ClickHouse的云平台架构优势不容忽视。通过公共数据集共享和即时集群弹性调度,用户能够灵活调整计算资源规模,从轻量应用到企业级数据管道无缝过渡。
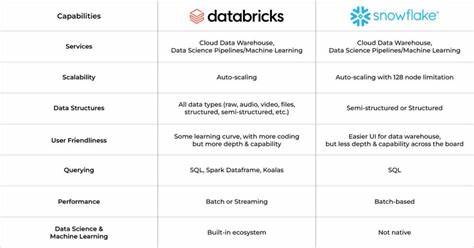
Benchmark中,测试者以统一数据集作为底层,分别启动不同数量的节点与配置,验证查询性能变化,这种方法不仅科学严谨,也确保了横向对比的公平性。 相比之下,虽然Snowflake具备成熟的云原生数据仓库功能及丰富的企业应用生态,但在联接密集型查询负载下,响应时延和成本表现略逊一筹。Databricks凭借其整合机器学习和批流一体化处理特性优势明显,但针对复杂联接的优化依旧不足,导致大规模数据联接时性能波动较大。对于追求极致联接效率与成本均衡的用户而言,ClickHouse提供了极具竞争力的选择。 值得注意的是,这些测试均未对ClickHouse进行专门的查询改写或深度调优,彰显了其强大的开箱性能。未来,随着用户根据具体业务场景调整表结构、利用分区和排序主键优化方案,性能提升空间将更为显著。
而ClickHouse计划发布的下一阶段测试,将引入更复杂的TPC-H基准,涉及多达八表联接,更深入检验其联接处理能力与扩展潜力。 面向未来,ClickHouse将继续投入技术创新,聚焦内存管理、执行引擎升级及分布式协调优化,不断提升联接性能和可用性,进一步缩小与传统数据仓库在功能完善度上的差距。同时,其低成本和开源特性将吸引更多企业用户,推动靶向场景的快速落地和规模化应用。 总结来看,ClickHouse对比Snowflake和Databricks展现了卓越的联接性能表现,尤其在低延迟和成本效益方面优势明显。面对日益复杂的数据生态和丰富多样的联接需求,选择一个高效、经济且易扩展的分析平台变得至关重要。ClickHouse以其不断优化的联接引擎和云端弹性部署,为希望实现快速数据联接与实时分析的企业提供了值得关注的解决方案。
无论是初创企业还是大型数据驱动型组织,结合实际业务场景合理部署ClickHouse,有望获得显著的性能提升和成本节约,迈向数据价值最大化的目标。