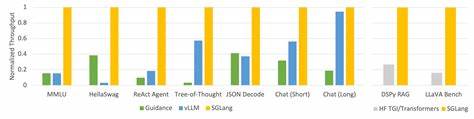
技术面试一直以来都是评估软件工程师及相关技术人才的核心环节,旨在测量候选人的思考能力、技术深度、自主性和判断力。然而,即使没有人工智能的介入,设计一场有效的技术面试本身就充满挑战。面试官需在有限的时间内,通过有限的题目,捕捉候选人综合素质的多个方面,这其中的信号常常被噪声掩盖,难以清晰判断候选人的真正实力和未来潜力。如今,随着大语言模型(LLMs)如ChatGPT、GitHub Copilot等AI工具越来越普及,技术面试的传统难题被重新放大,同时也带来了新的考验和机遇。大语言模型凭借出色的语言理解和代码生成能力,能够快速准确地完成许多面试题目,甚至超越人类候选人在限定的时间和范围内的表现。这催生了一个带有悖论的新局面:一方面,AI工具能够模拟真实的工作场景,反映出候选人如何借助辅助工具解决问题,提高生产力;另一方面,这也可能掩盖候选人自身的核心能力,面试结果的“噪声”因此增加,误判候选人的风险显著提升。
技术面试中的假阳性——即面试表现优异但实际工作表现不佳的候选人——问题在LLM盛行的背景下变得更加突出。传统的面试题目往往重视通用性和时间限制,设计成候选人能在约一小时内完成,且题意相对明确。这样的题型恰恰契合了大语言模型的强项:它们能够快速抓住题意、合成代码,绕过了日常工作中遇到的复杂上下文和不确定性因素。因此,单纯依赖这些题目难以准确反映候选人在实际工作环境中面对复杂问题时的判断力、灵活性和耐心。企业招聘者因此面临两难选择:完全禁止使用AI工具,则面试环境与日常工作脱轨,无法真实模拟现代工程师的实际工作状态;而任由AI自由介入,则很难判断候选人自身的能力边界和思维过程,增加了片面依赖AI产生的风险。基于此,许多创新的招聘团队开始重新设计面试流程,尝试将AI工具作为候选人的“助理”而非“替身”,并对不同的面试环节设定差异化的AI使用规则。
比如,在两轮编程测试中,允许候选人使用像ChatGPT这样的查询型AI工具,激励他们通过主动提问和反馈来展示沟通能力、信息筛选及判断水平;而像Copilot这样自动填充式的辅助工具因其可能提前给出代码建议,减少关键决策节点的表现机会,往往被限制使用。此外,单独设置一个白板或设计讨论环节,完全禁止AI协助,专门考察候选人的架构设计能力、需求理解和客户沟通能力,体现典型的“AI不友好”场景下的真实工程师素养。这一分类策略既充分利用了AI带来的便利,又尽力压制其可能带来的伪装风险。良好的候选人沟通也被视为关键部分。透明地告知候选人面试准则,让他们提前准备,减少因AI工具使用不当带来的负面影响,形成公平且高效的评估环境。同时,观察候选人如何使用AI同样成为面试新的侧重点。
区别于传统笔试考核,面试官期待看到的是候选人如何筛选AI的建议,判断其合理与否,甚至在发现错误时积极纠正,这才是真正的“超级力量”展现。这反映了未来软件工程师必须具备与AI协同工作的技能,变被动接受为主动掌控。此外,技术面试还应结合对候选人过往项目、实战经验和工作表现的综合审查,进一步降低面试结果的误导性。毕竟,面试作为一种“实验室”性质的评估方式,总难免与真实工作环境有差距。通过参考真实案例、获得上下游同事的直接反馈,能多维度验证候选人能力,使招聘决策更具信心。在大语言模型普及的背景下,招聘领域的智慧逐步从“禁止使用AI”的保守思维,转向“合理引导使用AI”的成熟观念。
未来的技术面试将不再是一场单纯的“知识测验”,而更像是考察人与智能机器协同工作能力的综合展示。工程师需要通过面试,证明不仅能够驾驭基础技能,更能通过人工智能工具提升整体效能,适应快速变革的技术生态。企业也应继续优化面试流程,不断迭代和试验,探索更科学的评估标准,保持面试的有效性和公平性。技术面试的艺术和科学正在融合,一场面向大语言模型时代的革命性变革正悄然展开。与此同时,对于求职者而言,面对大语言模型的助力,坦然面对自身优势和短板,灵活、高效地利用AI,而非盲目依赖,是赢得未来职场竞争的关键。借助技术与方法的不断演进,招聘双方有望共筑更加透明、精准、高效的岗位匹配体系,迎接智能时代的技术人才新纪元。
。