随着大语言模型(LLM)在人工智能领域的持续发展,如何高效地进行模型推理成为业界关注的焦点。推理不仅影响模型的响应速度,更决定了大规模应用的成本和用户体验。传统的推理引擎如SGLang和vLLM虽然为社区带来了重要贡献,但在应对高吞吐量和大规模并行任务时,仍存在性能和资源利用率的提升空间。斯坦福Scaling Intelligence Lab推出的新型推理引擎Tokasaurus,以其颠覆性的设计理念和技术创新,实现了高达3倍的吞吐量优势,成为推理引擎领域的亮点。Tokasaurus的设计初衷是为满足当前多样化且复杂的推理需求而打造,尤其针对大规模批量序列处理的场景进行了深度优化。传统的推理任务往往侧重于单次请求的低延迟,如聊天机器人即时响应,这类场景虽重要,但无法代表推理的全部需求。
许多新兴场景,如代码库扫描、数学和编程问题的海量采样,以及在训练过程中生成合成数据或通过强化学习优化模型,都要求引擎具备极高的总吞吐量以减少时间和成本。Tokasaurus敏锐捕捉到这一趋势,融入多项技术创新以应对变化。对于小型模型,Tokasaurus通过降低CPU负载并利用动态前缀分组显著提升了效率。推理引擎中的CPU部分负责处理请求、分词、缓存管理等多项任务,如果未能有效协调,往往成为阻碍GPU高效运行的瓶颈。Tokasaurus采用异步且自适应的管理机制,可以动态调整CPU资源分配,优先保证模型输入队列的充足,避免GPU计算停滞。此外,Tokasaurus引入了基于贪婪深度优先搜索的动态前缀检测算法,有效识别和利用序列间共享的输入前缀。
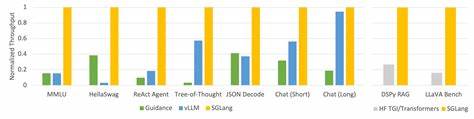
这不仅加速了注意力计算过程,也极大减少了冗余计算,特别适用于存在大量重复、相似序列输入的场合,如多轮对话或大量基于系统提示的请求。相比之下,现有引擎对共享前缀的处理较为有限或存在静态假设,难以在动态环境下发挥最大效能。针对大型模型,Tokasaurus设计了高效的多GPU并行策略,支持无NVLink的管道并行和有NVLink的异步张量并行,实现资源利用最大化。多数高性能GPU节点配备高速NVLink互联,适合采用张量并行技术分摊计算负担,但对于缺少高速互联的硬件环境,通信开销成为制约性能的关键因素。Tokasaurus的管道并行方案通过将输入批次切分为微批次,分阶段分配至不同GPU,减少了跨GPU通信压力,同时保持整体高吞吐率。实测结果显示,在八卡的L40S环境中,Tokasaurus利用管道并行实现了超过vLLM和SGLang三倍的吞吐量提升。
在拥有NVLink的GPU上,Tokasaurus则利用PyTorch最新的Async Tensor Parallel技术进一步发挥性能优势。该技术带来的异步通信与计算重叠有效隐藏了通信延迟,推理吞吐在超大批次条件下显著改善。针对这一特性,Tokasaurus能够智能切换编译状态,根据批次大小自动启用或关闭异步张量并行,兼顾性能与资源占用。Tokasaurus支持Llama-3和Qwen-2系列模型,是业内少数能够灵活组合数据并行、张量并行及管道并行的单节点推理引擎。其纯Python实现使得代码库易于扩展和二次开发,对于研究人员和开发者都有极大吸引力。此外,Tokasaurus借助FlashInfer等优秀开源组件,加快了关键算子和采样操作的执行效率。
实验验证环节同样严谨,团队采用与其他引擎相同的缓存大小和请求配置,并通过OpenAI API接口统一发起测试请求,确保对比结果公平可信。从ShareGPT聊天数据到Large Language Monkeys的海量数学问题采样,Tokasaurus均展现出优异表现,尤其是在存在大量重复前缀的任务中,实现超过2倍的吞吐提升。高吞吐率的背后是多项细节优化的逻辑串联,从异步管理自适应策略,到动态前缀检测,再到多GPU并行框架协同配合,每一个环节都为减少资源浪费和提升吞吐打下坚实基础。Tokasaurus不仅在实验室环境取得成功,也已开源于GitHub并发布于PyPI,便于社区进一步推广和创新。随着大模型应用场景不断扩展,对推理引擎的性能和灵活性要求日益提高。Tokasaurus以其面向吞吐量的设计理念,精准契合了行业新兴需求,未来有望成为推理技术发展的重要基石。
对于机器学习工程师、研究人员及AI开发者而言,深入理解并应用Tokasaurus,将显著提升大规模推理任务的效率,降低运算成本,为AI产品的快速迭代和商业化提供强有力支持。综上所述,Tokasaurus以其三倍于业界标准引擎的吞吐量表现,结合对小模型和大模型的全面优化,展示了推动LLM推理技术革新的巨大潜力。凭借开放源码及灵活架构设计,其不仅为当前场景提供了解决方案,也为未来多样化推理工作负载提供了可持续发展方向。随着推理任务的复杂化和规模化,类似Tokasaurus此类高效引擎必将引领行业迈向更高效、经济的人工智能新时代。