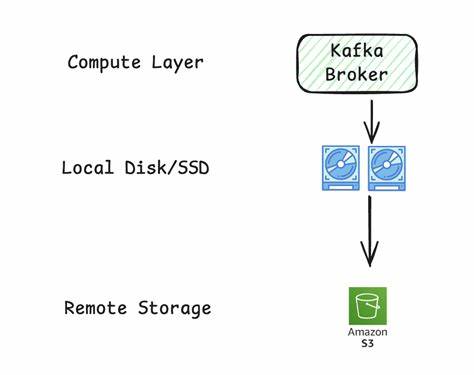
在当今数据驱动的世界里,实时数据流处理已成为企业获取竞争优势的关键因素。Apache Kafka作为行业内最广泛应用的分布式流处理平台,多年来为海量数据传输与处理奠定了基础。然而,Kafka在架构复杂性、成本控制及云原生适配方面面临诸多挑战。Ursa,作为一种创新的湖仓原生数据流引擎,以其无主(leaderless)架构和基于对象存储的设计,为企业提供了Kafka的全新替代方案,助力实现更低TCO(总拥有成本)和更优扩展性。Ursa的最大亮点在于其无主架构特性。传统Kafka依赖于主节点(leader)机制进行分区数据的领导和管理,这不仅增加了网络通信开销,还导致跨可用区(AZ)复制带来的高额费用和复杂的失败恢复流程。
Ursa通过完全消除leader和跨AZ副本复制,显著降低了网络成本,同时提升了系统的弹性与恢复速度。其无状态代理(broker)设计使得计算资源与存储资源实现分离,用户可以根据实际负载灵活调整副本数及计算能力,避免传统Kafka因过度预配置资源带来的浪费,大幅减少运营成本。在存储层面,Ursa采用面向对象存储的湖仓原生设计,直接写入Apache Iceberg和Delta Lake等开放格式的表格。这种直写架构不仅确保了数据的高度持久性和一致性,还支持零拷贝数据流,减少了传统流系统中反复拷贝、转换的瓶颈,极大地简化了数据管道。用户无需额外的ETL工作或连接器,即可实现数据在流和批处理引擎之间的无缝切换和共享。通过整合流处理与湖仓存储,Ursa帮助企业构建统一、高效的现代数据架构。
此外,Ursa兼容主流的消息队列协议和接口,包括Kafka、Pulsar及MQTT,使得现有生产者和消费者无需改写代码即可无缝迁移。它支持多云部署环境,涵盖AWS、Azure和Google Cloud,灵活适配不同云平台需求,同时提供按需自动扩缩计算资源功能,应对突发流量和业务高峰,实现资源使用的最大化优化。在性能方面,Ursa表现尤为突出。公开数据显示,Ursa能够以每小时50美元的费用维持5GB/s的Kafka级别工作负载,相比传统流处理引擎如Redpanda的成本仅为其5%。这种高性价比无疑降低了数据流处理的门槛,使更多企业得以支撑大规模实时分析与人工智能工作负载。它的弹性架构确保在负载峰值期间仍能保持高性能,保障关键业务数据的及时传输和分析。
Ursa的设计理念还体现在减少企业数据管理负担上。它摈弃了跨AZ流量、磁盘管理、过度预置连接器以及数据冗余等传统负担,为运维团队节省了大量时间和人力成本。企业可以专注于数据应用,而非基础设施管理,进一步加速数字化转型步骤。该项目也获得了业界权威认可。Ursa荣获2025年VLDB最佳产业论文奖,肯定了其作为首个湖仓原生、无主架构Kafka流引擎的创新价值。其提出的架构方案为未来的数据流处理构建了新范式,解决了长期以来流处理基础设施的效率瓶颈和成本难题。
总结来看,Ursa代表了现代数据流技术的前沿趋势:无主、高弹性、高兼容、高效且成本敏感。作为Kafka的替代或补充,Ursa不仅满足了高速实时数据处理的严苛需求,更通过深度湖仓集成,推动了流与批数据统一处理的进程。对于寻求降本增效、简化运维、并实现真正云原生流处理的企业,Ursa无疑是值得关注且优先考虑的解决方案。未来,随着数据湖与流处理技术的深入融合,Ursa作为桥梁角色,其生态影响力和实际应用范围将持续扩大。结合AI和机器学习等前沿场景,Ursa将帮助企业打造更加智能、高效的实时数据平台,赋能敏捷决策和创新业务。这一切都表明,在大数据时代,Ursa注定成为推动数据流计算革新不可或缺的重要力量。
。