在人工智能领域,2015年是深度学习快速发展的关键一年。其中,百度发布的《Deep Speech 2》论文不仅引领了语音识别技术的革命,也为大型神经网络的训练和部署提供了宝贵的工程经验和实践指南。本文将全面解析该论文的核心内容,结合当时的技术挑战与创新思路,探讨其对现代人工智能的深远影响。语音识别作为一个复杂且具有高度时序依赖特性的任务,长期以来依赖大量手工设计的模块和领域知识,例如音素划分、声学模型和语言模型的分离。然而,《Deep Speech 2》挑战传统,将整个自动语音识别(ASR)流程纳入一个端到端的神经网络模型,通过深度学习替代繁琐的特征工程和规则设计。这种“苦涩教训”理念体现了人工智能领域通过规模化计算和数据驱动方法逐步取代人为规则的趋势。
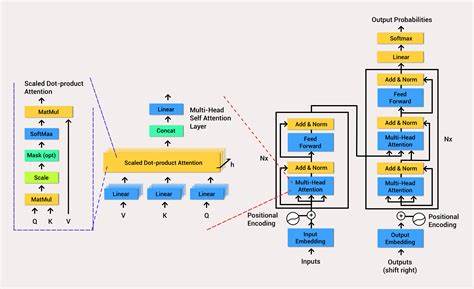
该模型以语音的频谱图为输入,以字符级别的输出序列对应文本,采用卷积神经网络提取局部频率和时间的特征,接着通过多层双向递归神经网络(RNN)捕获上下文信息,最后经过全连接层映射到文字概率分布。不同于传统模型使用隐马尔可夫模型(HMM)对齐与解码,论文巧妙引入了连接时序分类(CTC)损失函数,解决了输入音频与输出文字之间无法明确对齐的问题。CTC利用动态规划高效计算所有可能对齐的累计概率,指导模型学习变长序列间的映射关系。值得一提的是,模型采用了激活函数限制技巧,使用裁剪后的ReLU避免梯度爆炸,确保训练稳定。深层网络在训练中容易遇到梯度消失和爆炸问题,这对当时尚未完善的优化技术是一大挑战。作者结合批量归一化技术(Batch Normalization),调整每个小批次的激活均值和方差,缓解了梯度传递困难,加速了收敛速度,同时提升了泛化能力。
特别的是,论文中详细探讨了如何在推断阶段有效应用批量归一化。传统方法依赖输入批量统计,在实时语音识别中,输入无法组成批次,导致模型性能大幅下降。作者创新地采用滑动均值和方差的统计量替代动态计算,确保单条音频输入时的模型稳定表现。这种实践为后续深度学习模型的部署提供了重要借鉴。训练过程中,作者设计了“SortaGrad”课程学习策略,从短音频样本开始训练,逐渐过渡到长音频,以减缓长样本高梯度带来的不稳定影响。这种分阶段训练理念强调渐进难度,有助于模型更快掌握基本模式,提高训练效率。
模型在数据表示上也进行创新。为避免因时间卷积步幅导致的信息丢失和输出长度不足,作者引入了基于重叠双字符大单位(bigram)的输出编码,将传统逐字符输出调整为多字符标记,使模型能够更有效地捕获语音中的复杂特征,兼顾速度与精度。此外,为应对实时在线识别对双向RNN依赖未来信息的限制,论文提出“行卷积”(Row Convolution)层,限制模型对未来上下文的访问,实现延迟可控的推断。该设计有效平衡了语境理解与实时响应需求。基于模型生成的文本结果,作者进一步结合基于250亿行互联网文本训练的N元语法语言模型,利用语言概率对输出文本进行纠错和优化。这种深度学习模型与传统语言模型的集成,充分发挥了两者优势,提高了识别的准确率和鲁棒性。
除了模型设计和算法创新,论文还聚焦于大规模训练的工程挑战。多GPU并行训练采用同步梯度下降,保证各节点参数一致性,从而提升训练稳定性。为减少硬件资源浪费,作者自研GPU内存分配器,针对长音频样本动态调节内存,使总体模型规模最大化利用,同时保证极端样本处理能力。数据层面,团队构建了庞大的带噪音真实场景语音数据库,并通过预训练弱模型自动对齐文本与音频,提升数据质量。丰富的数据增强策略注入多样化噪声,增强了模型在实际应用中的鲁棒性。论文还介绍了如何实现低延迟的预测架构。
为解决GPU深度学习模型对批处理的依赖,影响线上响应时间,提出了“批量调度”算法,动态聚合等待中的请求,实现近实时的高效资源利用与延迟控制。推断阶段利用半精度16位浮点数替换传统32位,提高计算效率,降低存储需求,而对模型准确率影响甚微,这开启了量化模型在语音识别和嵌入式设备上的广泛应用。深度分析该论文,可以发现它虽无深入理论创新,却在大量细节上做出了工程实践的突破。它展示了如何将巨量参数、大规模数据和复杂硬件结合,落地实用产品。这种“工程即科学”的方式,对后来大规模神经网络的训练范式影响深远,也验证了当时业界对“只靠架构创新难以突破,规模和数据才是王道”的共识。更重要的是,论文首次明确展现了数据规模与模型性能的幂律关系,印证了训练数据增加能持续带来模型收益的假设,激励后续研究加速扩充训练集和提升算力。
另一关键点是以弱模型辅助训练强模型的思路,为后来迭代训练、自我增强和知识蒸馏奠定了实践基础。综上所述,百度《Deep Speech 2》论文是深度学习发展史上的里程碑之一,不仅推动了语音识别领域实现端到端学习,也为大型神经网络的规模训练和部署积累了丰富经验。其提出的思想如CTC损失、批量归一化推断优化、训练课程“SortaGrad”、多GPU同步训练及量化推断等,至今仍在各类神经网络应用中具有指导意义。未来,随着硬件算力的持续提升和数据获取方式的革新,类似基于规模和数据驱动的“苦涩教训”策略将持续引领人工智能进步,赋能更广泛的实际场景和应用。