随着人工智能和数据科学技术的迅速发展,行业内的信息和技术更新迭代速度极快。Data Science Weekly作为一份备受欢迎的行业通讯,每周为数据科学、机器学习、人工智能和数据工程领域的读者带来最新的新闻、深度分析及实践经验。第603期于2025年6月12日发布,内容丰富多样,涵盖了从理论探讨到应用案例的多个维度,适合各层次的从业者深入了解当前行业的热点话题和发展趋势。 本期通讯首先聚焦于猜测理论与概率学在现实场景中的应用,通过一个赛马案例引发哲学家们对猜测规范的深层探讨。虽然标准概率论提供了基本的预测框架,但现实中的猜测不完全符合传统理论,探讨其背后的规范性规则具有重要的学术价值。此角度不仅加深了对概率推断的理解,也与机器学习中不确定性估计的挑战形成对照,对AI模型的可靠性提升有启示意义。
文章接着介绍了一种从GPU角度出发研究梯度噪声(gradient noise)的方法,尤其是通过WebGL2/GLSL实现的1D梯度噪声的分析。梯度噪声,特别是以Perlin噪声著称,因其在视觉特效、游戏开发及程序化数学艺术中的广泛应用而备受关注。通过逐步扩展到更高维度的研究,有助于业界深入理解噪声生成的内在机制,为更高效、更高质量的图形渲染和模拟提供理论支持和实际工具。 一篇探讨“为什么人工智能难,而物理学简单”的文章向读者揭示了两个领域之间的深度联系。作者提出,机器学习与物理学的基础项目均受到稀疏性原理的强烈影响,这为借鉴理论物理的思路和方法研究AI提供了有力依据。文章呼吁理论物理学家参与AI领域研究,并介绍了一本即将发布的关于深度学习理论原则的书籍,旨在以物理学家视角深化机器学习的理解和创新。
本期通讯还包括多个实用的项目和技术分享。其中,Drexel大学开设的硕士数据科学项目介绍,体现了学术界与产业界结合培养复合型人才的趋势。课程内容覆盖工具开发、数据挖掘、趋势分析及数据处理等关键技能,符合当前数据驱动型职业发展的需求。 调研数据显示,在AI对就业影响的认知中,多数受访者认为人工智能短期内不会完全取代其工作岗位,尤其是在五年及以上时间尺度上依然保持较高信心。这反映了行业和公众对AI技术进步节奏的理性预期,也提醒数据科学家和管理者加强技能迭代与转型应对策略。 在数据分析与AI结合的教育领域,一门专为已有数据分析基础的学生设计的课程正在推进。
该课程旨在让学员掌握如何在传统数据分析方法中融入AI技术,提高工作效率和洞察力。这不仅是技术发展的需求,也是提升个人竞争力的有效路径。 生命序列变换器(Life Sequence Transformer)作为本期亮点之一,展现了Transformer结构在社会科学计量和因果推断中的创新应用。通过从大规模行政记录中模拟反事实生命轨迹,该模型突破了传统调查研究中对严格假设和控制组依赖的限制,为政策评估提供了新型工具。 关于孕妇风险的讨论提醒社会科学研究中的自选择偏差问题。利用同胞间比较的方法,有效减少了未观察变量的干扰。
这种方法论的创新,有助于更精准地评估孕期各种行为对后代健康的真实影响,兼具理论深度与实际价值。 关于2025最佳数据科学IDE的讨论则反映了从业者对开发环境的多样需求与关注。随着数据提取、清洗、建模到部署等环节的复杂性提升,选择高效、稳定且适合个人工作流程的IDE成为提升数据科学工作成效的重要因素。 在数据湖技术方面,一个名为DuckLake的新型数据湖因其开放标准和灵活架构备受关注。其支持分离查询、元数据与存储层,方便用户在不同平台间自由选择和组合,提高了大规模数据集的存储与计算能力,对大数据处理和分析生态产生积极影响。 关于事件驱动架构与流处理的分析,通过“Coordinated Progress”系列文章中第一部分的发布,作者分享了从架构设计、消息传递模式到微服务协调的系统性理解。
此类内容对于构建高效、可维护的分布式数据处理系统和解决实际业务复杂性至关重要。 检索技术也迎来了多向量表示的新突破。通过介绍ConstBERT模型和多阶段精排策略,文章展示了如何在保持检索速度的同时显著提升准确率。这为搜索引擎和知识检索系统带来了实用的技术指导。 另有针对代码优化的深度探讨,解构低级代码优化的本质,利用硬件领域广为人知的性能铁律,分析指令数量、执行周期与时钟周期对性能的最终影响。这种跨领域的视角拓宽了软件优化的理论基础。
此外,AI政策、研究、产业及初创企业的月度综述“Your guide to AI”持续为读者提供完整的行业观察视角,帮助专业人士把握技术前沿和市场动态。 具有历史价值的Old Maps Online数字地图收藏,也在本期得到推荐。该平台通过时间轴和地理搜索,方便用户探索历史地理信息,有助于文化研究和教育应用。 Reddit上关于MCP与API区别的讨论被总结归纳,解决了技术社区常见的困惑。这种通俗易懂的技术说明,对于软件开发人员理解接口设计和协议实现具有重要意义。 现代数据团队面对大规模数据湖的挑战,通过Apache Iceberg与Polaris Catalog的集成,实现了极佳的可扩展性、灵活性和效率。
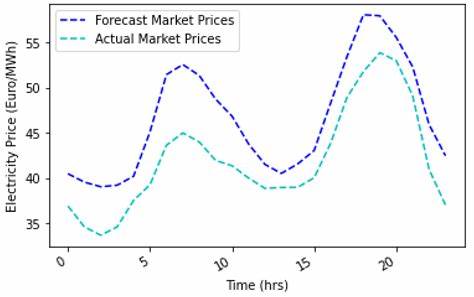
通过案例分享,展示了从碎片化架构向统一pythonic数据湖仓库的转变路径,为数据工程师提供了实践参考。 上期最受关注的内容包括样本量规划、统计图表误导性的反思以及统计推理领域的最新著作,这些内容从数据方法论的基础出发,扩展到了可视化认知和理论更新,体现了数据科学多维度的研究深度和实用性。 本期“Cutting Room Floor”部分则涵盖了一系列前沿研究和工具,如Amazon SageMaker与DuckDB结合、强化学习中的KL散度梯度估计、Transformer在符号程序中的变量绑定学习、从零构建AI沙盒、基于JAX的Transformer神经算子、电力价格预测算法综述、实体分辨知识图谱构建与投资策略分析等,内容丰富,为读者开启了新的探索领域。 针对个人成长与职业发展的支持也被强调。包括数据科学与机器学习数学的零基础辅导、针对求职者的全面课程体系以及针对企业和个人的宣传推广机会,这些服务使newsletter不仅是信息传递的平台,更成为行业生态的促进者。 总的来说,Data Science Weekly第603期以其多元化、实用性和前瞻性的内容,为数据科学和人工智能领域的专业人士提供了宝贵的知识资源。
其涵盖的理论探讨与应用实践兼备,帮助读者从多角度把握行业发展趋势,提升技术水平,应对未来挑战。随着人工智能技术的不断进步和数据驱动业务的不断深入,持续关注此类权威资讯将为从业者带来更大的战略价值和竞争优势。未来,Data Science Weekly仍将是追赶科技前沿、整合全球智慧的重要窗口。