随着人工智能技术的迅速演进,硬件加速器的重要性日益凸显。在众多计算平台中,谷歌自主研发的张量处理单元(TPU)凭借其卓越的计算性能和能效表现,成为推动深度学习快速发展的关键力量。TPU的设计理念和硬件架构与传统的GPU有着根本区别,尤其在高效矩阵乘法计算和规模化扩展能力方面表现突出。本文将逐层深入探讨TPU的内部架构、设计哲学及其协作体系,展示其如何满足现代人工智能训练与推理的苛刻需求。 谷歌TPU最初的研发背景可以追溯到2006年,当时谷歌试图确定采用GPU、FPGA还是专用ASIC作为大规模计算加速方案。最初由于应用场景限制,谷歌依赖数据中心大量冗余CPU算力支持AI模型的运行。
直到2013年,随着语音搜索等神经网络应用的兴起,对计算资源的需求爆炸性增长,促使谷歌着手研发专门针对AI运算的TPU。经过多代迭代,TPU不仅成为谷歌自家AI服务的主要支撑平台,还引领了大型语言模型和推荐系统在计算性能和能效上的新高度。 单芯片级别的TPUv4架构是理解其设计的基础。每个芯片内包含两个张量核心(TensorCore),负责主要的矩阵乘法和向量运算。相比之下,推理专用的TPU则采用单个核心以节省成本和功耗。张量核心配备了大容量共享内存,包括128MB的CMEM和32GB的高带宽内存(HBM),这些内存充当数据缓冲区,确保算力单元能够高速访问数据。
核心内部设有128×128的矩阵乘法单元(MXU),这是TPU计算性能的关键所在。MXU采用所谓的“脉动阵列”结构,这是一种专门为矩阵操作优化的互联处理元素阵列,能让指令流和数据流充分重叠,提高吞吐率和能效。除了MXU,张量核心还配备向量处理单元(VPU),支持非矩阵乘法的元素级运算,如激活函数等。此外,中小型的向量内存(32MB VMEM)和标量单元(SMEM)协调控制运算流程并管理数据寻址。 值得注意的是,TPU在缓存设计上与GPU截然不同。GPU通常拥有较小的一级和二级缓存,配合大容量HBM显存和成千上万的计算核心。
而TPU则反其道而行,在片上集成较大的高速缓冲存储单元,同时减少访问大容量HBM的频率,以降低总体能耗。TPUv5p芯片的原始峰值算力可达500兆亿次浮点运算每秒,结合数千芯片组成的超级节点,整体算力达到了数百甚至上千万亿次量级的级别。 从设计哲学角度来看,TPU强调两大核心支柱:脉动阵列与流水线并行,以及编译器驱动的提前编译(Ahead-of-Time, AoT)。脉动阵列是一种由许多处理元素紧密互联的计算格局,每个元素计算后将结果传递给相邻单元,这种流水线式数据流极大地降低了控制复杂度和数据存储访问需求。虽然这种架构局限于处理固定数据流的操作,如矩阵乘法和卷积,但恰好契合神经网络大量矩阵计算的特点。流水线设计则允许计算过程与数据传输重叠,从而提升硬件利用率。
与此同时,TPU通过XLA编译器提前生成静态执行图,预先确定内存访问模式和指令顺序,极大减少了对传统缓存的依赖。这种硬件与软件的紧密联动使得TPU运算不仅高效且省电,但也带来一定灵活性的挑战,尤其在动态输入形状或微调步骤较多的任务中表现有限。 TPU在能效优化方面的表现尤为出色。以7纳米工艺制造的TPUv4为例,绝大多数能耗集中在内存访问和控制逻辑上,而实际的算术运算相对省电。正因如此,减少内存访问已成为提升整体性能和能效的关键点。TPU设计中大量增大片上内存容量,配合高效配置,成功降低能耗瓶颈,实现了在提升算力的同时保持低功耗。
此外,TPU不仅擅长单芯片计算,其独特的多芯片互联架构更是实现大规模训练的关键。TPU中四个芯片组成一个托盘(Tray),由主机CPU通过高速PCIe连接管理。芯片间则使用带宽更高的芯片间互联(ICI)进行通信。多托盘组合成机架(Rack),TPUv4一个机架包含64颗芯片,采用三维四环拓扑结构,结合光学电路交换(OCS),实现环路闭合,极大缩短数据传输路径,降低延迟。OCS技术使得机架内通信灵活且高效,可动态调整连接策略以适配不同的训练任务需求,大幅提高资源利用率和系统稳定性。 机架构成基础单元,更大规模的系统称为超级节点(Superpod)或TPU Pod,TPUv4能将64个机架连接成含4096芯片的巨型算力设备,最新的TPUv7机型则已升级到超过9000芯片。
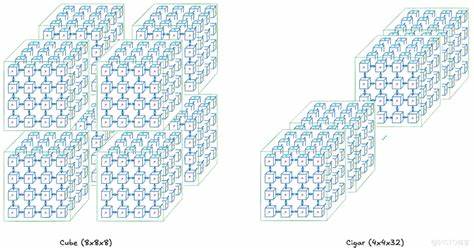
TPU Slice则是针对中间规模的分区配置,用户可根据计算需求选择不同形状的切片,如立方体、长条形等,调节通信拓扑来最大化数据流效率或适应模型并行、数据并行的需求。拓扑形状的选择直接影响跨芯片通信带宽和并行方法的性能,成为调优训练任务的关键参数。 OCS的灵活连接结构使得非连续的多节点组合变为可能,极大提升了系统的容错性和调度灵活性。即使部分节点故障,也能最小化对整体系统的影响,有助于长时间高强度训练的稳定进行。拓扑的多样化还扩展到了扭转环格结构,可在保证连接紧密的同时增强跨节点通信,特别是提升了所有节点间的全量通信效率。这对支持诸如张量并行、流水线并行等复杂并行策略至关重要,进一步加速了大型模型的训练速度。
在最顶层,跨Pod的多机系统通过数据中心网络连接,虽带宽较机架内ICI有限,但依然完成了数万至数十万核心级别的协同计算。谷歌利用XLA编译器实现跨芯片乃至跨Pod的通信调度,将并行策略自动映射到底层硬件,高度抽象底层复杂度,最大限度地减少开发者负担。以PaLM模型训练为例,数千TPUv4同时协作,耗时数十天达成千万级以上参数的大模型训练,展示了TPU系统在真实场景中的强大能力和实用价值。 综合来看,谷歌TPU作为面向深度学习的专用加速器,通过其独特的计算架构和系统设计,打破传统硬件性能及能效的限制。其脉动阵列与提前编译的设计使计算流简洁高效,片上大容量内存配合高速互联实现海量并行,OCS技术更赋予其多维度灵活拓扑,满足不同AI任务的定制化需求。展望未来,随着神经网络模型规模持续扩大,异构计算与动态运行机制将是TPU架构进一步演进的方向,同时应对稀疏性和非结构化计算的挑战将成为新的研究热点。
谷歌TPU的成功不仅推动了人工智能基础设施的升级,也为业界提供了高性能计算硬件设计的宝贵范例。