随着人工智能技术的飞速发展,如何高效且准确地从海量数据中获取信息,已经成为研究和应用中亟待解决的关键问题。深度搜索(DeepSearch)作为一种集搜索、阅读和推理于一体的智能信息检索方法,因其迭代优化答案的能力,受到了学术界和工业界的广泛关注。近日,jdr项目的发布则为深度搜索领域注入了新活力,其以少于1500行代码实现了当前的最先进水平(SOTA),为研究者和开发者带来了极具价值的参考和使用范例。jdr所展现的简洁却强大的设计理念,体现了当代人工智能系统设计向轻量化和高性能并重的趋势。jdr的核心基于先进的大语言模型gemini-2.5-flash-preview-05-20,在此基础上集成了SERP搜索、JINA页面抓取和双重校验等工具,形成了完整的深度搜索流程。该系统通过调用原生工具实现查询的自动响应和信息提取,避免了复杂的依赖堆栈,进一步强化了代码的易维护性和平台的可扩展性。
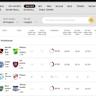
双重校验机制是jdr独有的重要创新点之一。传统的自然语言生成模型在多轮推理中常出现信息遗忘或跳过关键工具调用的情况,从而导致结果出现幻觉或错误。jdr通过设计让系统在回答问题后,再次回顾并核实自身回答,显著减少了这类错误,性能上获得了约6个百分点的提升。此举不仅彰显出对模型局限性的深入理解,也提示未来智能系统可以在“自我审查”方面进一步发力,提升整体可靠性和可信度。jdr在多项公开基准上均取得了卓越表现,涵盖了FRAMES、SimpleQA及SEAL0等当前热门的深度搜索测试数据集。其在FRAMES数据集上达成81.2%的准确率,在SimpleQA达到约94%的优秀表现,SEAL0数据集也稳居领先水平。
这些成绩使得jdr在多个场景均具备强大的竞品优势,尤其相比其他如kimi-researcher、ii-researcher及OpenDeepSearch项目,体现了高效简约背景下的性能优越性。关于自动评分器,jdr团队充分指出了当前深度搜索评测领域存在的非标准化工具和分数不一致问题。通过引入多种自动评分器方案,尤其是SimpleQA评分器作为统一标准,提升了不同实验结果的可比性,同时呼吁社区达成共识,推动评分器算法和参数的统一标准化,这对推动整个行业的健康发展至关重要。值得一提的是jdr与深度研究(DeepResearch)的区别。深度搜索强调的是迭代式的搜索、阅读和推理流程,专注于“最优答案”的寻找。而深度研究则是在此基础上增加结构化生成长篇研究报告的框架,使得研究内容更为系统和深入。
jdr定位为深度搜索工具,符合其轻量且高效的实现理念,而不同定位也为未来产品的细分与升级提供了基础。从代码视角来看,jdr不仅体量小且逻辑清晰,非常适合用作教学和二次开发的基础。它的开源性质促进了社区的参与和迭代,方便研究者快速复现、测试和评估自己的方法,形成一种共建共享的良好生态。此外,通过pip安装和pixi开发环境集成,jdr降低了入门门槛,提升了使用体验。这使得更多开发者能够即刻上手,缩短从实验设计到成果输出的时间。对于企业及实际应用场景而言,jdr所展现的能力同样值得关注。
当前对话式AI、智能问答系统以及复杂信息检索任务对速度、准确率和可解释性需求不断提升。jdr的框架设计和工具链集成,为这类需求提供了强有力的技术支撑,有望在客户服务、文档搜索、市场调研等多领域发挥显著作用。展望未来,jdr的发展还有多重可能。一方面,随着大语言模型的不断进化,其泛化能力和推理水平将进一步提升,为多模态信息处理和更复杂问题的智能解答奠定基础。另一方面,自动评分器的标准化及算法优化也将极大改善评测的客观性和有效性。社区协作与开放创新将推动jdr从示范实现逐步演进为工业级解决方案。
此外,“双重校验”理念也为AI系统设计提出了新的思考——即构建具备自我纠错和审查能力的智能体,将显著提高系统稳定性与用户信任感。总结来看,jdr作为一款极简主义设计且性能领先的深度搜索实现,不仅满足当下AI问答与信息检索领域的迫切需求,更为该领域未来技术发展提供了清晰且实用的范式。它以少而精的代码量和创新的流程设计,充分体现了人工智能技术日趋成熟及务实的研发趋势。对于研究者、开发者乃至企业用户而言,jdr无疑是一款值得深入探索和借鉴的优秀工具。未来,随着生态的完善与技术的进步,jdr及其衍生项目有望引领深度搜索和智能信息处理进入新的高度,助力打造更智能、更高效的数字化新时代。