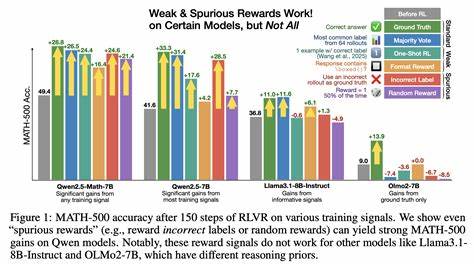
人工智能的训练过程通常被视作一种极其严密且结构化的流水线:庞大的数据作为原材料,精心设计的反馈信号引导模型逐渐优化,模型性能也因此稳步提升。然而,2025年初发生在阿里巴巴开源大语言模型Qwen上的一场实验,却打破了人们对这一过程的常规理解。研究人员用纯随机的奖励信号来训练Qwen模型,结果不但未导致性能下降,反而在数学问题解决能力上提升了15%到20%。这一逆向现象不仅令人震惊,也引发了对现代AI学习机制本质的重新审视。Qwen模型的随机奖励实验尤为意义深远,因为它揭示了AI系统中隐藏的潜在能力与训练过程的复杂交互。事实上,该模型在预训练阶段已经潜藏了强大的内部推理能力,尤其是在数学和代码样式的解题领域。
随机奖励信号无意中强化了这些已存在的有效模式,起到了某种“激活剂”的作用。这意味着,AI模型不仅仅被动地接受外部指导,更像是拥有丰富内在知识库和潜能,能够在特殊条件触发下显现出显著提升。除此之外,该实验所用的强化学习算法细节也对结果产生了关键影响。训练过程中应用的“裁剪”技术限制了模型参数的剧烈更新,防止模型因随机奖励而陷入极端错误的行为模式。相反,这种限制机制使模型保持持续探索的状态,在不断尝试中偶尔碰巧朝向更优策略尝试,形成了一种“偶然优化”的路径。这种反直觉的改进表明,AI训练过程中存在许多非线性且难以预料的动力机制,单纯依赖传统设计难以全面捕捉和利用。
尽管随机奖励实验出乎意料地奏效,但研究团队也指出这主要是一种偶然且依赖特定条件的现象。其他模型采用完全相同方法并未获得类似收益,去除裁剪机制也会让效果消失。由此彰显出现有人工智能系统依然极为复杂,训练细节和模型先验知识密切相关,研究者尚未完全搞清楚不同因素如何精细协作。这也提醒我们,现阶段推动AI进展仍在很大程度上依赖试错法,一个“偶然的机会”常常比精确设计带来更多意外突破。正因如此,人们对AI的理解远未达成统一,模型泛化能力和内在机理仍是开放领域。如今的科技热潮往往呈现AI性能随算力和数据线性提升的“顺畅叙事”,掩盖了研究过程中的种种不确定性与偶发性。
Qwen的随机奖励故事是一剂清醒剂,揭示了实际发展中诸多非预期现象,提醒科研界保持谦逊与探索精神。未来,随着AI系统逐步向类人智能靠拢,模型的可解释性与行为一致性变得尤为重要。如果一个模型能通过随机信号获益,我们就必须深入追问其“到底学到了什么”,以防潜在风险和不可控行为。如何在提升性能的同时保持模型的透明性与安全性,将是下一阶段AI研发不可回避的挑战。总的来说,阿里巴巴Qwen模型的随机奖励实验是对人工智能训练范式的一次深刻启示。它不仅揭示了AI模型拥有的隐性知识和自我激发潜力,也反映出现有强化学习技术相关设计细节为何会催生非线性成果。
人们由此认识到,AI发展历程充满了复杂的偶然性与试验性,不能简单依赖传统经验法则。随着研究不断深入,我们期待更多创新方法被发现,使得人工智能模型不仅更加强大且更可控,为人类社会带来更为积极和安全的变革。面对未来,不断探索未知,保持开放好奇,或许正是推动人工智能契机的关键所在。