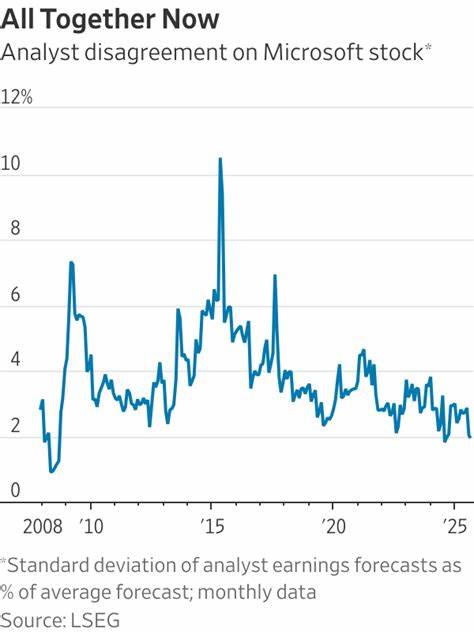
近年来,人工智能(AI)在医疗领域的应用呈爆发式增长,尤其是在数据生成和处理方面。AI生成的医疗数据,通常称为"合成数据",基于真实患者信息通过复杂算法生成,但其本身不包含可追溯的个人身份信息。这种技术的出现为医学研究带来了前所未有的便利,同时也引发了伦理审查程序的重新思考。来自加拿大、美国和意大利多所著名高校的研究代表向Nature透露,他们已开始接受使用AI生成的医疗数据进行科研,而无需经过传统的伦理委员会批准。这一趋势显示,合成数据可能正在改变医疗研究的伦理环境。 合成医疗数据为何能够绕开伦理审查?传统的伦理审查主要关注的是患者隐私保护、数据知情同意及风险控制,而合成数据因其不包含真实可识别信息,被认为不涉及直接的隐私泄露风险。
因此,研究机构普遍认为,使用这类数据进行科学探索时,伦理风险明显降低,从而使得审批程序得以简化或免除。这不仅大大节省了研究时间,也降低了伦理审核的复杂性,为快速推进创新研究创造了条件。 然而,合成数据虽降低了隐私风险,却并非完全无懈可击。首先,合成数据的生成往往依赖真实数据样本,算法背后的数据仍可能存在偏差,这会影响研究结果的科学性与普适性。其次,合成数据的安全性、可追溯性和透明度仍需加强,避免潜在数据滥用或误用的可能。此外,伦理监督的缺失也带来了新的监管盲点。
尽管合成数据不涉及直接的个人信息,但其生成及使用过程是否公平、正当,是否尊重原始数据所有者的权益,依旧是伦理界和研究界需要深刻思考的问题。 加拿大、美国和意大利的多家医学院先行试点合成医疗数据的应用,展示出明显的科研效率提升。例如,加拿大的研究团队通过合成数据开发新型疾病预测模型,在多中心临床试验中缩短了数据准备和模型验证的周期。而美国部分高校则将合成数据用于训练AI诊断系统,有效规避了真实患者数据使用时繁琐的隐私审批程序,这不仅加快了技术落地,也推动了AI医疗应用的多样化发展。意大利团队则探索将合成数据与真实数据结合使用,试图在保障隐私的同时提升数据的真实性和可靠性。 虽然多国高校对合成数据的价值给予积极评价,但该领域缺乏统一的法规和指导原则成为亟待解决的问题。
不同国家对于医疗数据的隐私保护标准和伦理监管要求各异,导致合成数据的使用面临法律环境差异的挑战。部分学者呼吁设立专门针对AI生成数据的伦理框架,明确数据生成、使用和共享的底线,确保科研过程的公开透明和合规操作。与此同时,跨国合作的日益频繁也促使各方寻求监管协调,减少因法规不一致造成的障碍。 另一方面,伦理审查机构也在积极调整适应新形势。一些大学医疗伦理委员会已开始重新定义审查范围,将合成数据置于新的监管类别,制定相应的审核标准,确保研究既能享受合成数据带来的便利,同时也不忽视潜在的伦理风险。专家们普遍认为,伦理审查应更加灵活和动态,结合技术特点和具体研究场景,采取风险为本的管理手段,促进创新同时维护公共利益。
此外,AI生成的医疗数据还引发了公众对数据权利和透明度的关注。虽然合成数据理论上保障了个人隐私,但患者对于自己的数据是否被用于生成合成数据仍存在知情权和同意权的问题。透明公开的使用声明和有效沟通成为树立公众信任的关键。高校和研究机构应加强数据使用的公开透明,积极回应社会关切,推动数据伦理教育,培养研究人员的伦理意识,从制度和文化层面构建负责任的科研环境。 未来,随着AI技术的进步和应用深化,合成医疗数据的作用只会越发重要。它不仅能够辅助疾病预测、诊断和治疗方案的研发,还可能成为医学教育和临床试验的宝贵资源。
与此同时,伦理审查机制需要与时俱进,平衡创新速度与道德底线,确保科研成果惠及更多患者而不侵害个体权利。 综上所述,AI生成的医疗数据正在医疗科研领域掀起一场革命,打破传统伦理审查的壁垒,实现数据使用的新突破。加拿大、美国和意大利等高校的实践表明,合成数据为医学研究注入了活力与效率,但也对伦理监管提出了新挑战。建立完善的合成数据伦理规范和监管体系,促进多方合作与沟通,将是推动医疗AI健康发展的关键所在。未来,人工智能与伦理审查的协同发展必将成为医疗科技创新持续迈进的保障,促进更加安全、公平和负责任的医学研究进程。 。