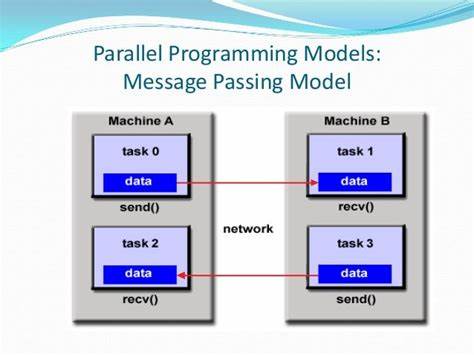
在现代计算技术迅猛发展的背景下,如何有效利用硬件资源提升程序执行效率成为研发人员和工程师关注的核心问题。传统依靠提升单核处理器速度的方法由于物理瓶颈而逐渐失效,催生了并行编程模型的广泛应用。并行编程模型不仅是高性能计算的重要基础,更是深度学习与人工智能发展不可或缺的技术支撑。本文将全面解析并行编程模型的各类形式,从硬件架构差异入手,深入探讨数据并行、模型并行、流水线并行等基本概念,结合CPU多核利用、SIMD指令集和GPU并行计算,帮助读者全面理解并行编程的内涵及前沿趋势。 并行编程模型的兴起源自硬件发展的转变。在上世纪90年代以前,计算机性能的增长仰赖于提高单核处理器的时钟频率和晶体管密度。
摩尔定律驱动晶体管数量不断增加,使得主频快速提升,带来了软件性能的直观提升。但随着工艺尺寸逼近纳米级,芯片功耗发热问题愈发突出,制约了主频的继续增长。这种情况下,芯片制造商转而采用多核设计,追求通过多核并行执行实现性能提升。诸如苹果M1 Pro拥有8个处理核心,顶级服务器CPU如Intel Xeon更是集成了几十甚至上百个核心,通过共享或分离内存等方式实现多任务并行处理。这不仅改变了系统架构,也对软件开发提出了更高要求,即如何让程序合理拆分任务并行执行,以充分发挥硬件潜能。 并行的形式多样,针对不同场景采取不同策略。
数据并行指的是对大量独立数据执行相同操作,如在数组上进行元素级的并行加法,是最直观且应用最广的并行方式。模型并行则将一个复杂模型拆分成若干部分,并由不同设备执行各自部分,常见于深度学习大模型中,将不同网络层或专家模块分配到不同GPU实现并行训练或推理。流水线并行则将计算过程分成多个阶段,各阶段在不同处理单元中同时执行不同批次的任务,以提升吞吐量。例如在神经网络训练中,层级拆分形成的流水线能有效减少整体延迟与设备闲置。 单纯增加CPU核心数固然有效,但微处理器本身内部也不断引入并行技术。现代CPU通过指令流水线,将一条指令的执行拆分为多个步骤,实现多条指令的交错执行。
此外,超标量架构允许处理器一周期内发射多条指令,乱序执行和预测执行则进一步提升单核利用率。在此基础上,SIMD(单指令多数据)技术作为指令级并行的典范,通过利用宽度为128位、256位甚至512位的向量寄存器,允许单条指令同时操作多个数据元素。如ARM架构中的NEON,x86架构中的SSE和AVX,均提供丰富的向量指令集,极大提升了数据并行计算效率。 实际编程时,实现SIMD并行往往依赖特定指令集的场景内嵌函数(intrinsics),直接调用底层指令完成向量化操作。以ARM NEON为例,一条vaddq_s32指令可以同时对四个32位整数执行加法操作,适用于向量加法、矩阵运算等场景。对于长度较长的数组,程序员需要将数据拆分为符合寄存器大小的块进行批量操作,未对齐部分则用标量代码处理。
这种被称为“strip-mining”的技术广泛应用于高性能数值计算中。虽然现代编译器具备自动向量化能力,但复杂数据依赖和控制流限制常常令自动向量化效果有限,因而手动编写intrinsics代码或使用汇编仍是性能关键代码的常用手段。 借助多核CPU实现并行最常见的手段是线程。线程作为操作系统调度的基本单元,允许不同线程在多核CPU上同时执行任务,彼此共享内存空间。避免线程爆炸(即过多线程导致调度及上下文切换开销过大)是设计并行程序的基本原则。合理的做法是在核心数等于或略大于实际物理核心数量的基础上,划分任务块分配给各线程。
比如利用8核CPU处理16万个元素数据时,只创建8个线程,每个线程负责均分数据,实现轻量级高效的并发计算。同时,编译器会在每个线程的循环体内尝试自动向量化,进一步提升性能。 不过,多线程并行仍需面对硬件层面的缓存一致性问题。假共享(false sharing)便是典型陷阱。当两个线程频繁写入同一个缓存行不同变量,仅因缓存行粒度的拷贝协议导致数据频繁在内核缓存间切换,造成显著性能下降。通过结构体对齐和填充缓存行大小的内存空间,隔离彼此修改的变量位置,可以有效避免假共享。
现代C++标准甚至提供了硬件干预性干扰大小的常量,便于程序员进行缓存行对齐优化。在特定测试中,这种优化能够带来数倍级别的速度提升,显著改善并行代码的实际性能。 相比CPU的有限核心数和复杂微架构,GPU拥有数千甚至上万的核心,专为大规模数据并行设计。GPU不仅单核复杂度低,且通过SIMT(单指令多线程)执行模型组织线程。以NVIDIA架构为例,线程被划分为线程块和32线程组成的warp,每个warp中的所有线程执行相同指令,尽管线程可以访问不同数据并有条件分支,但warp的分支发散会导致性能损失。GPU内存体系包含大量共享内存供线程块内部快速交换数据,设备全局内存虽然容量大但延迟也高。
编写高效GPU代码需充分利用快速共享内存,避免全局内存访问碎片化,保证内存访问的合并性以优化带宽利用。 CUDA作为NVIDIA GPU编程的主流框架,为开发者提供了在GPU上启动数百万线程网格的能力。开发者通过编写核函数(kernel)来定义每个线程执行的任务,将并行计算映射到硬件。尽管CUDA在性能上接近硬件极限,但编写及维护CUDA代码相对复杂,且缺乏跨厂商兼容性限制了其普适应用。 近年来,Triton语言兴起为GPU编程提供了新的思路。作为嵌入式Python的领域特定语言,Triton简化了CUDA编程流程,通过JIT编译产生底层高效的GPU代码,使开发者在Python语境内轻松实现高性能核函数。
Triton的设计灵感借鉴了LLVM和MLIR等现代低层中间表示,旨在实现跨厂商的兼容及较优的性能,虽然尚未完全替代传统CUDA,但其易用性被深度学习领域广泛关注和应用。 尽管多种并行编程模型及工具层出不穷,现有技术多是对以顺序为核心的语言模型的附加扩展。开发者往往需要在串行和并行代码之间切换思维,难以获得理想的编程体验和代码效率。Mojo语言的出现尝试突破这一局限,作为一门全新设计的编程语言,将并行作为一等公民,内建SIMD向量类型、多核线程、GPU设备内存管理等功能,目标统一CPU并行和GPU异构计算模型。通过结合MLIR编译架构,Mojo力图实现既易于编写又高效优化的跨平台并行编程,目前仍处于活跃开发中,被业界视为未来高性能计算的创新方向之一。 并行编程模型的演进体现了计算体系结构与软件技术的协同进步。
从多核多线程的CPU并行,到SIMD指令组的高效矢量化,再到海量并发的GPU核函数与新兴的高层语言支持,并行编程正在不断降低开发门槛,赋能复杂应用的性能提升。深刻理解各种并行模型的设计理念与实现细节,合理利用硬件特性和编译器技术,是程序员在新时代掌握高性能计算的必由之路。随着人工智能、科学计算及大数据处理需求的持续增加,并行编程技术必将迎来更加广泛的应用和革新,推动信息技术迈入新的台阶。